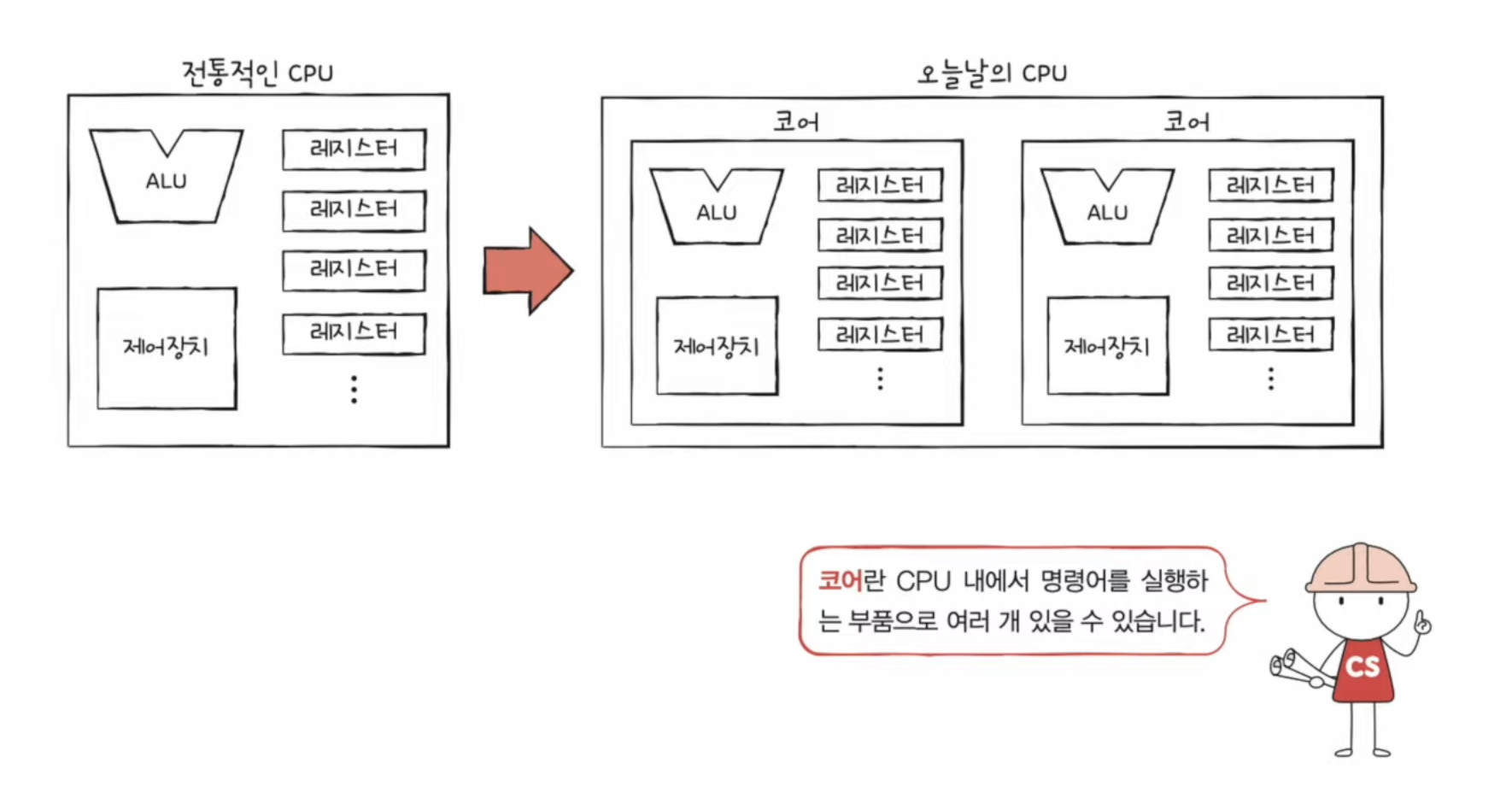
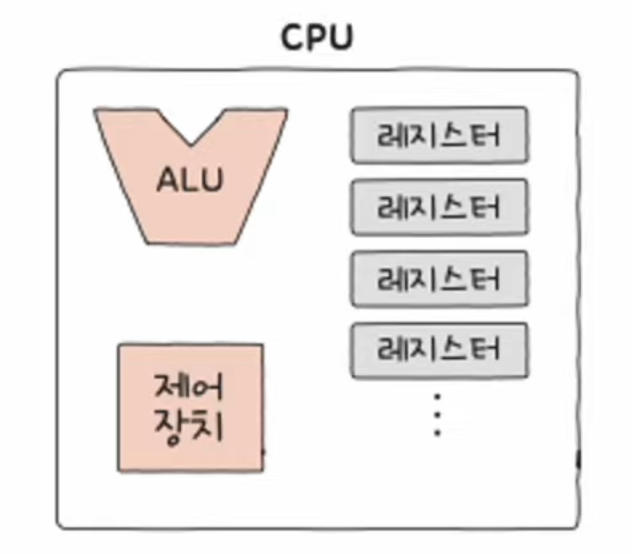
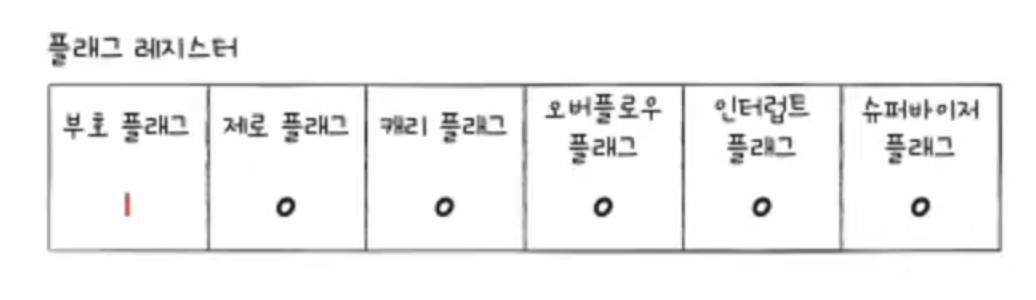
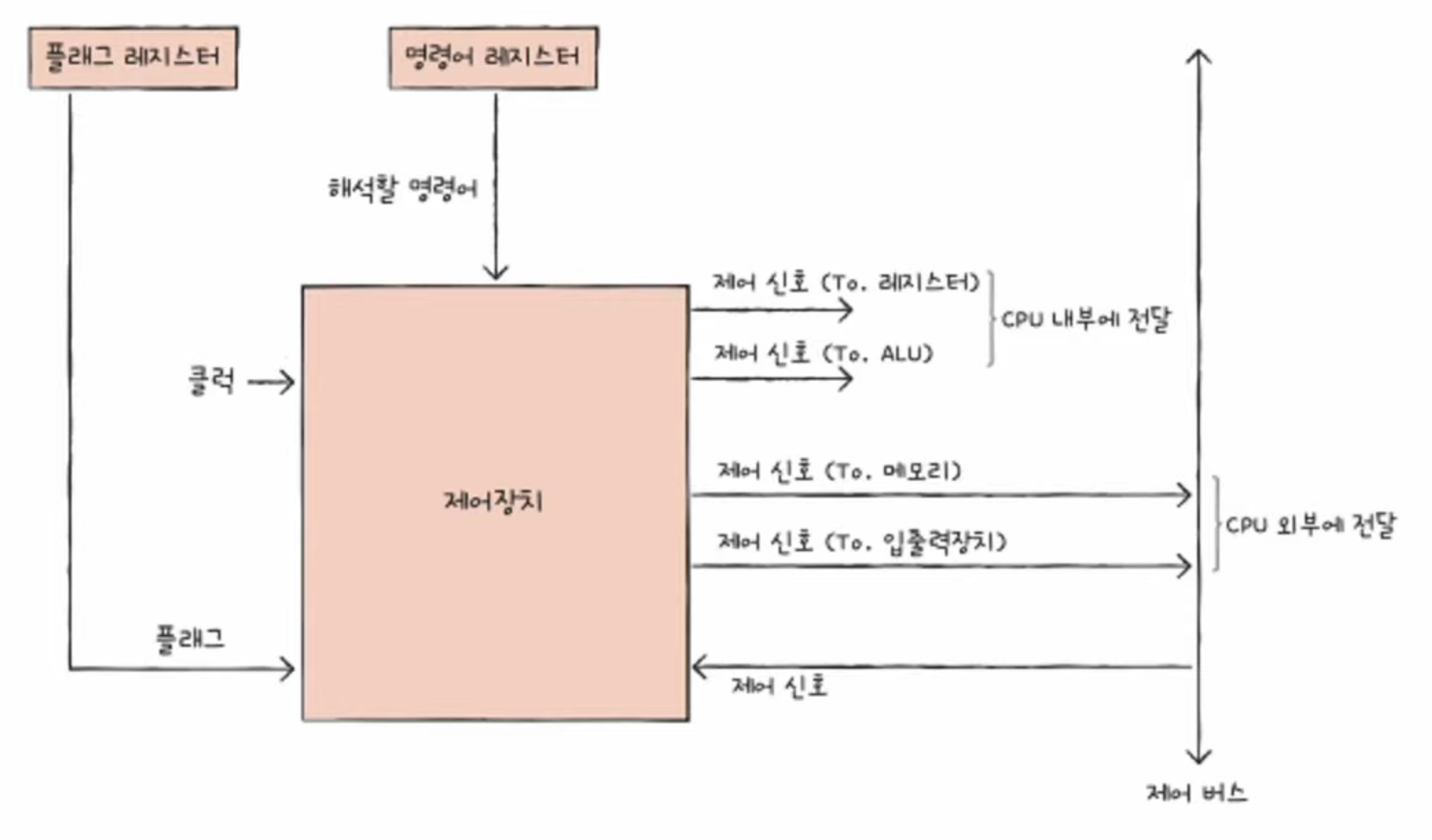
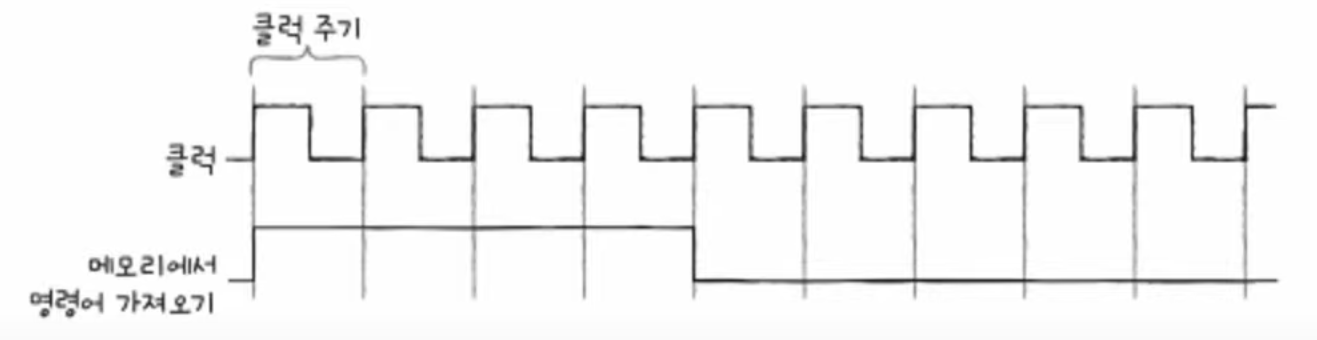
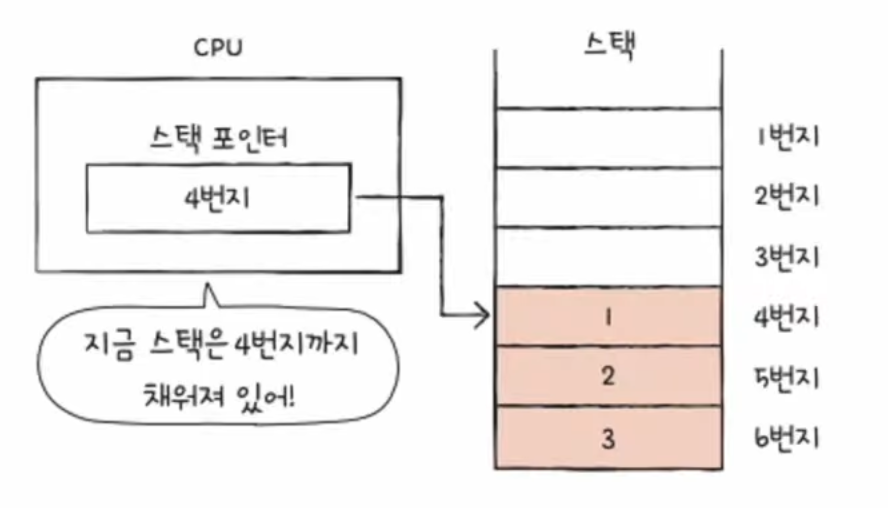
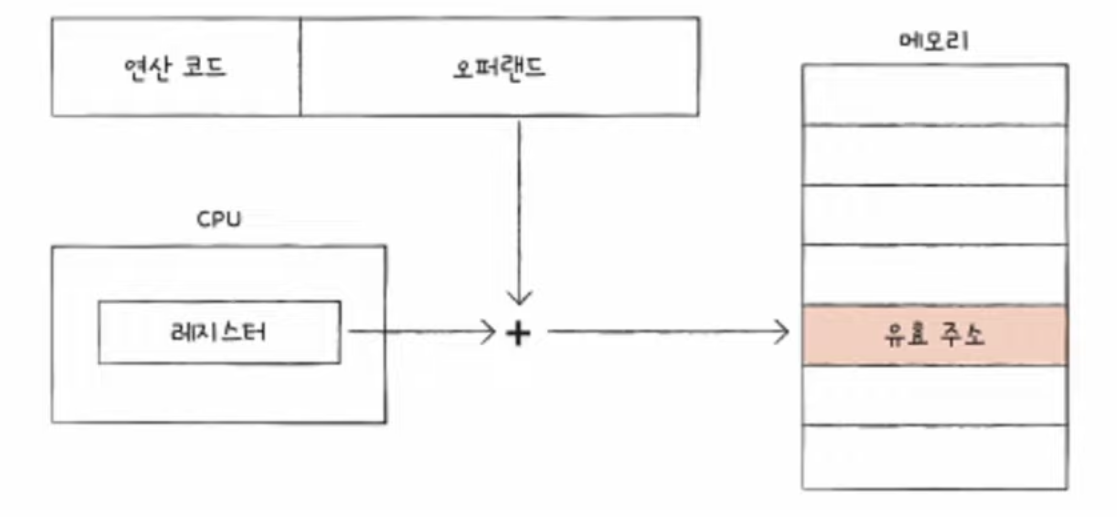
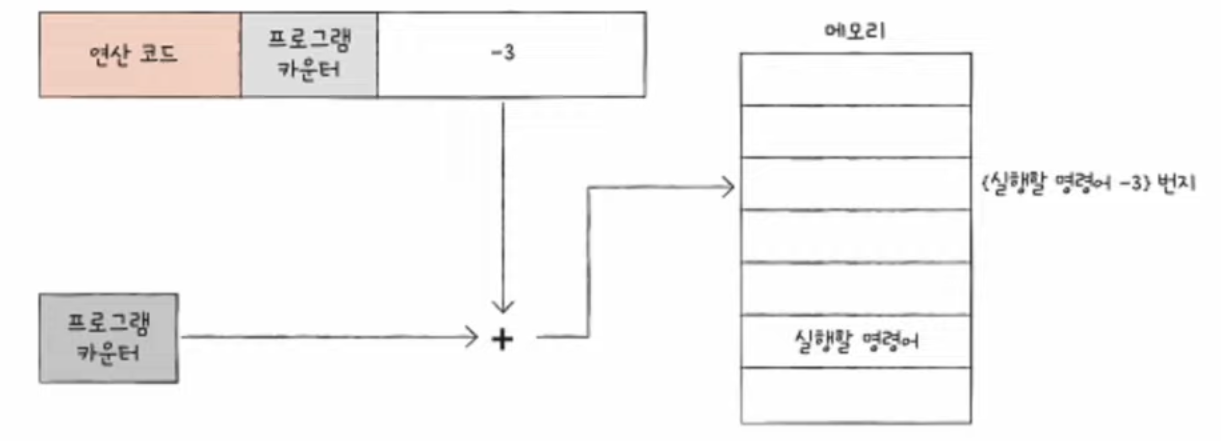
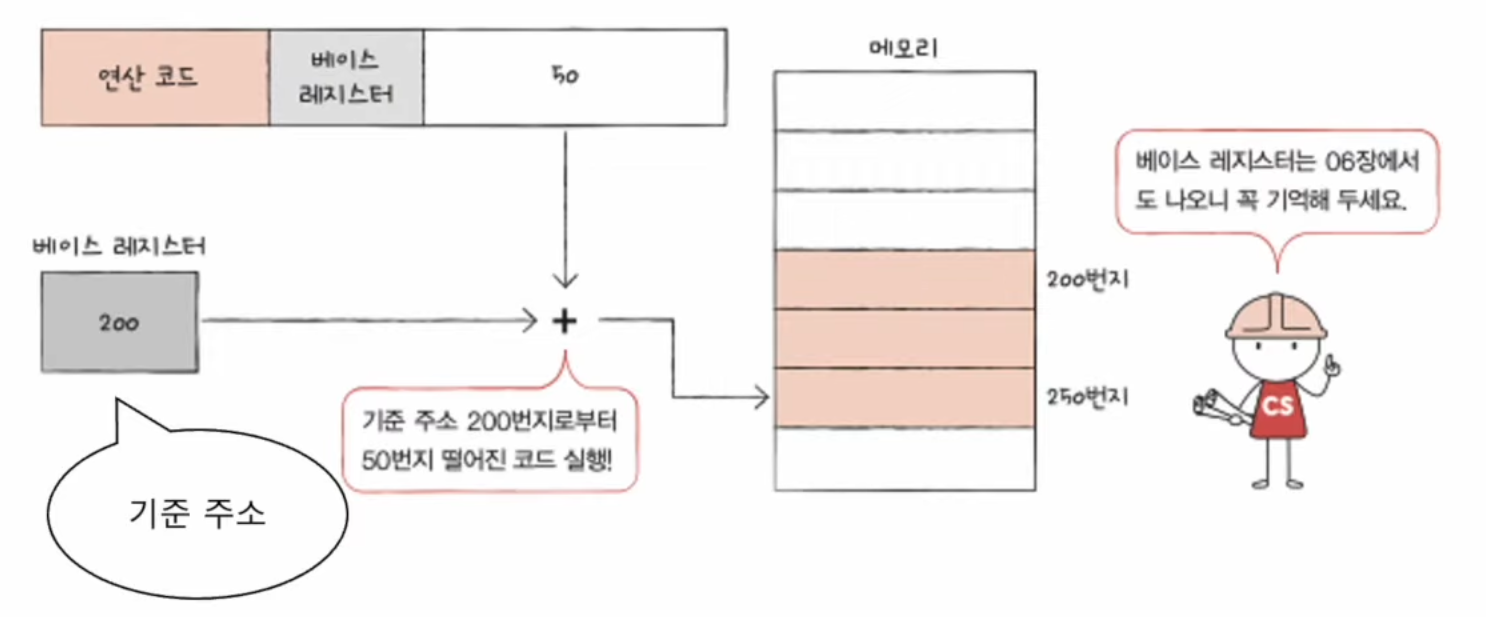
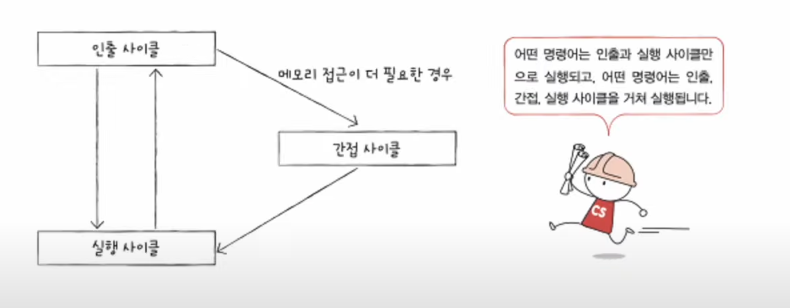
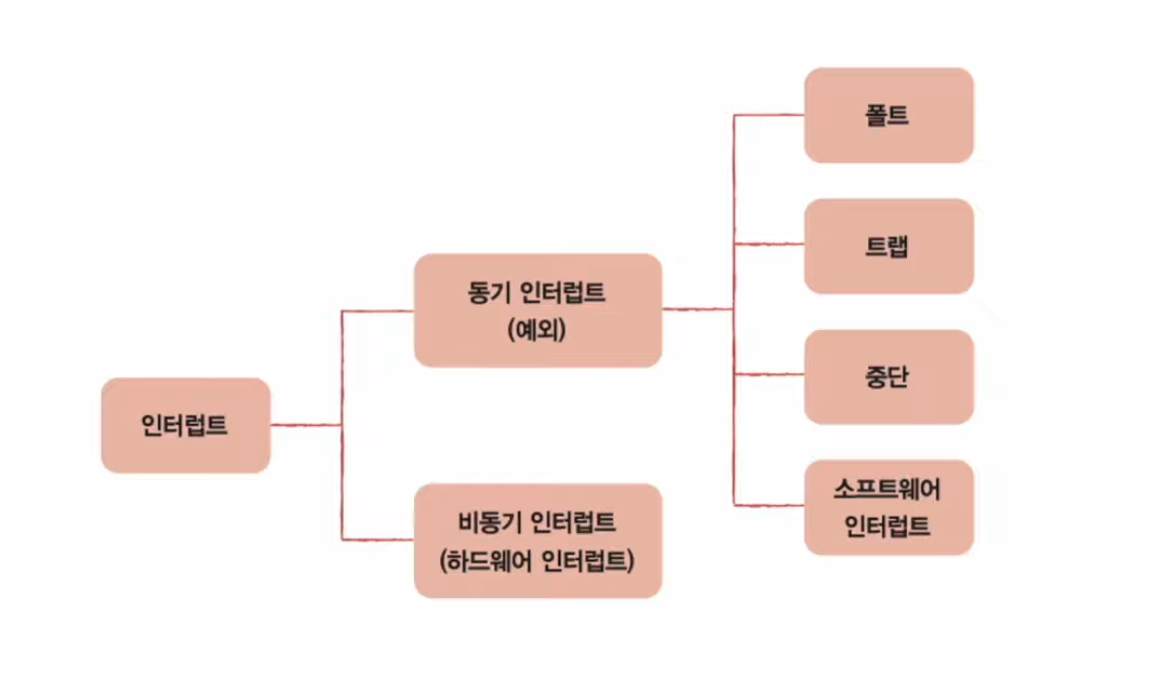
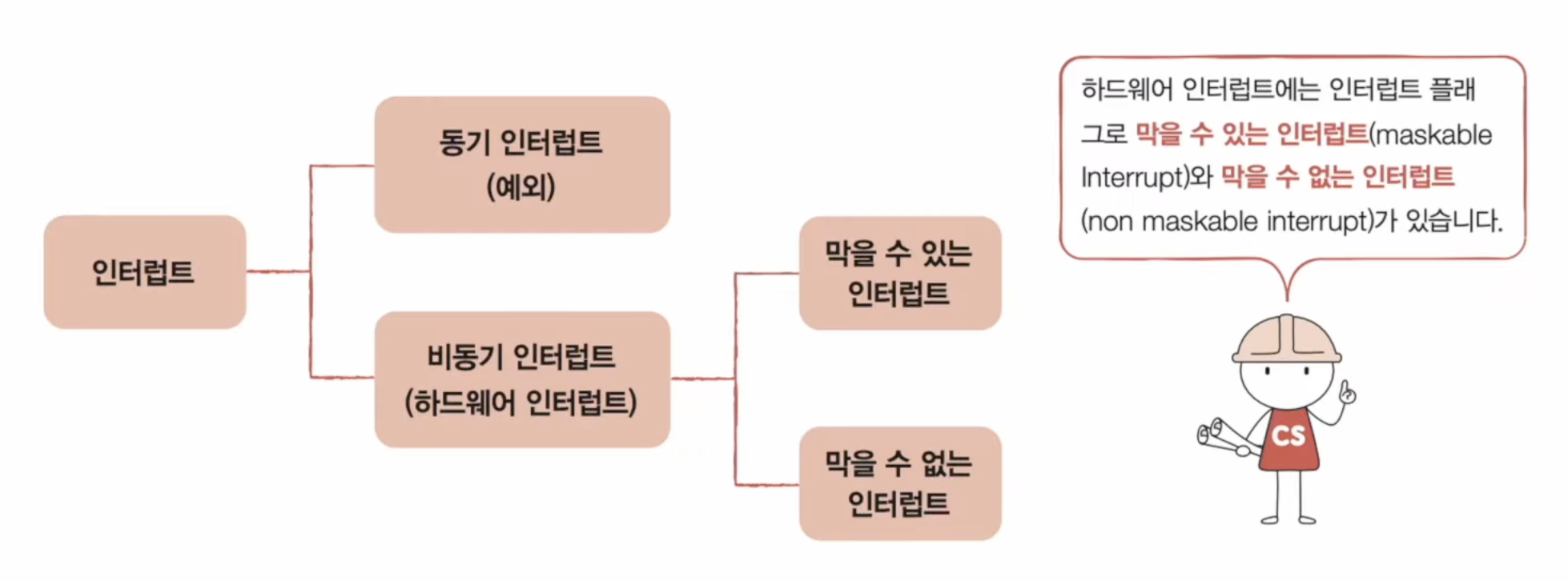
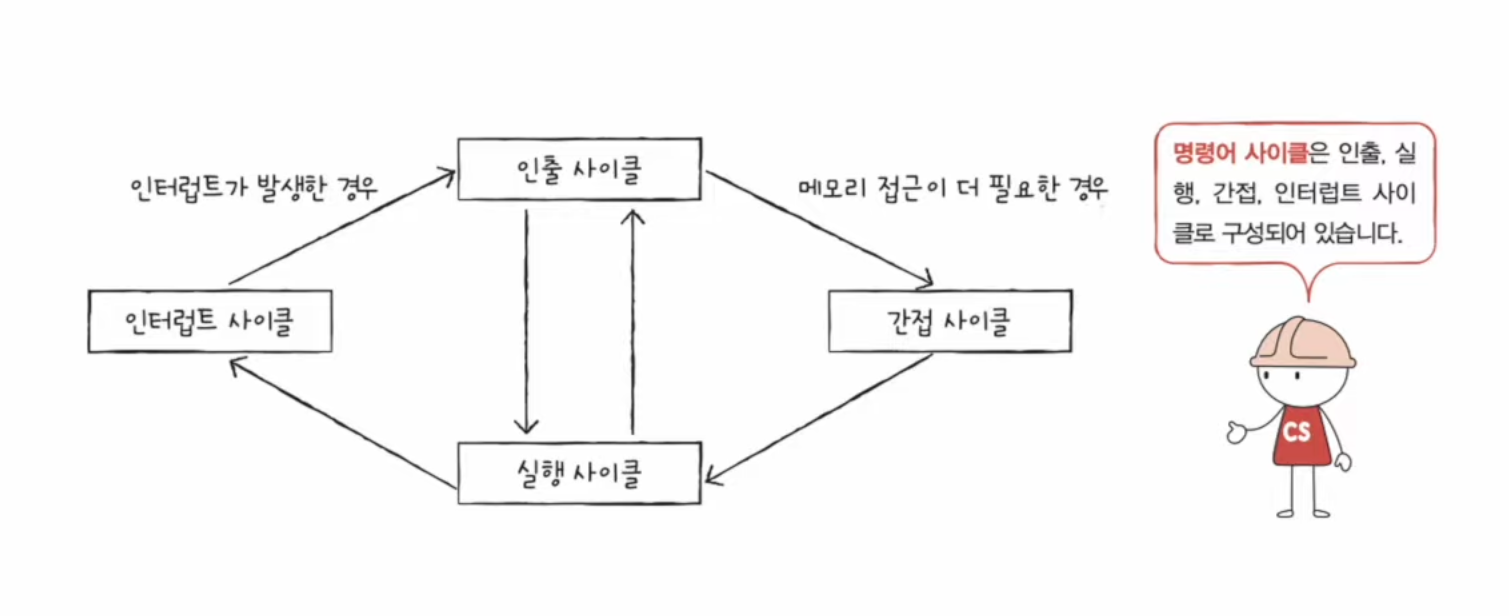
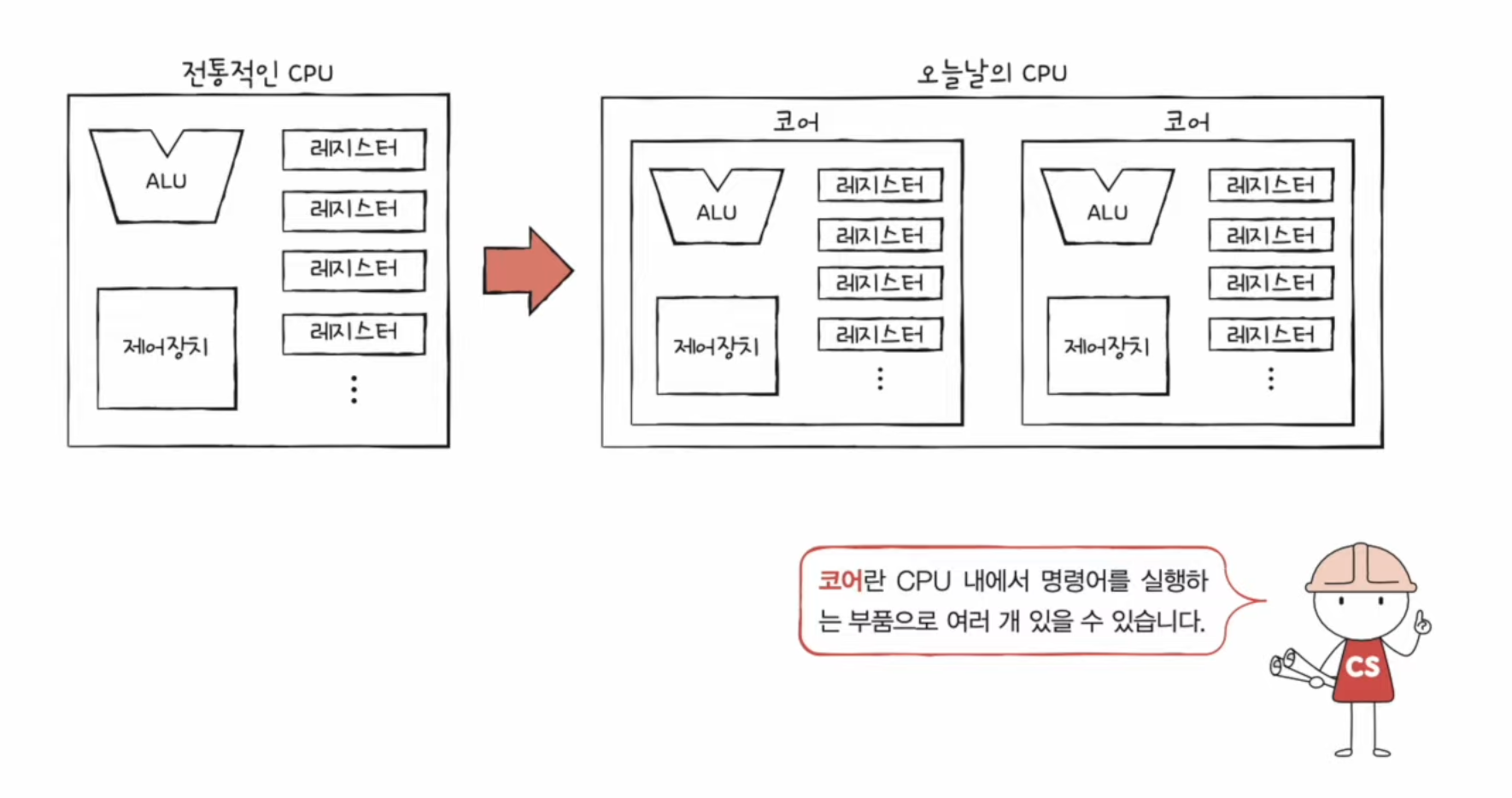
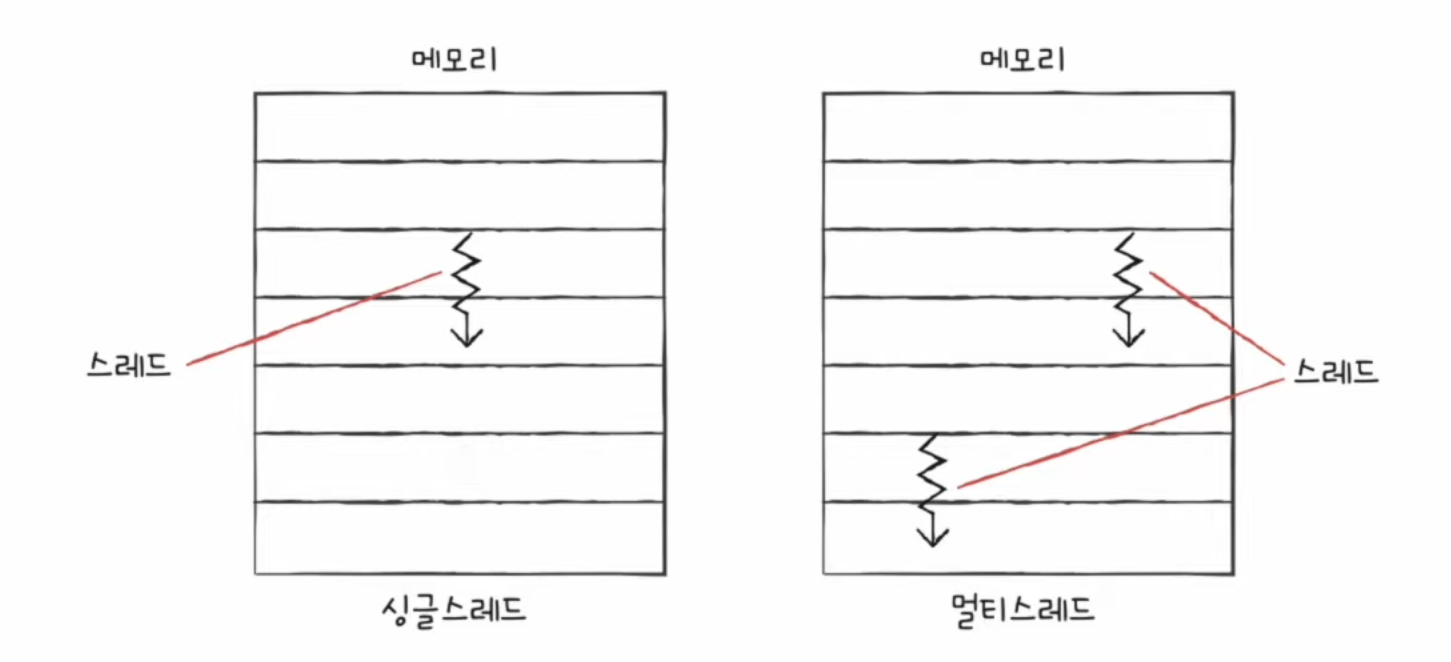
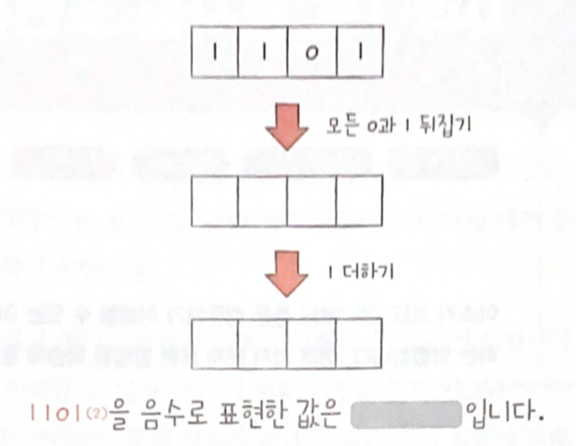
📃 기본 미션1
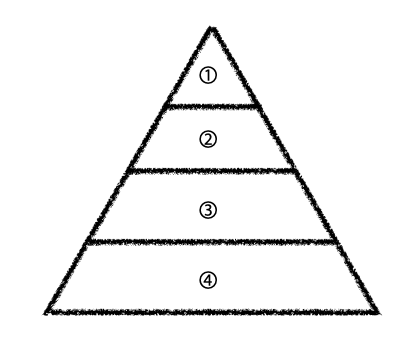
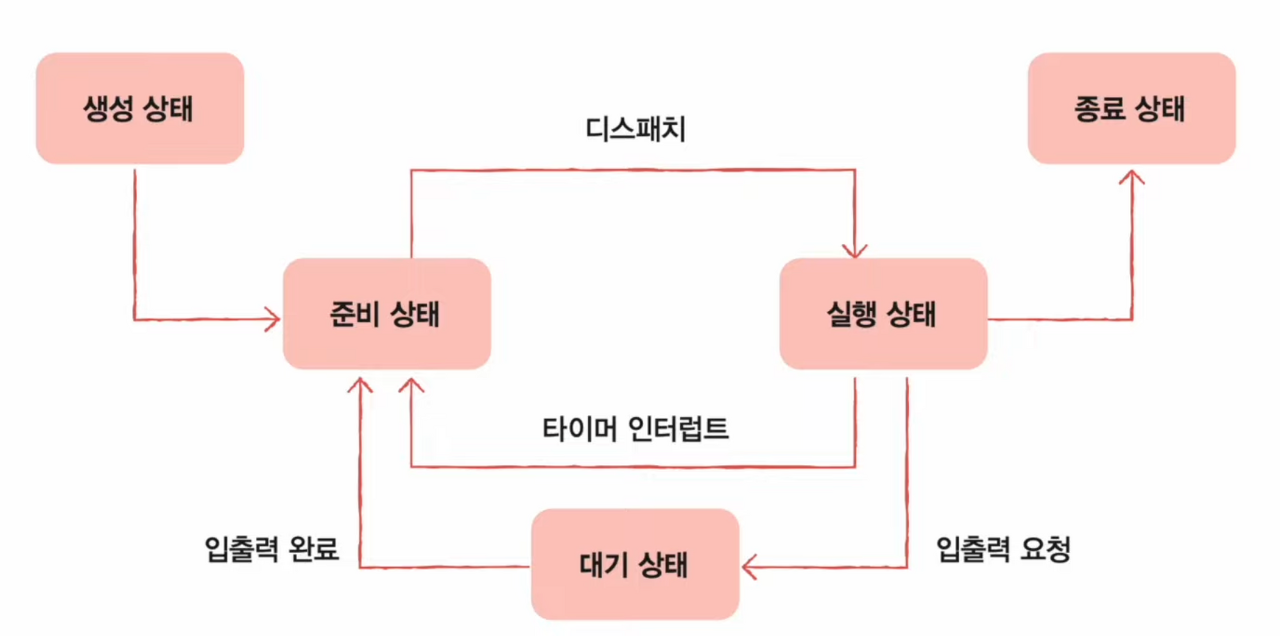
p.304, 확인 문제 1번 ) 다음은 프로세스 상태를 보여주는 프로세스 상태 다이어그램입니다. ① 부터 ⑤ 까지 올바른 상태를 적어 보세요.
🖍 )
① = 생성 상태
② = 준비 상태
③ = 실행 상태
④ = 종료 상태
⑤ = 대기 상태
📃 선택 미션
Ch.11 (11-2) 준비 큐에 A, B, C, D 순으로 삽입 될 때 선입 선처리, 최단 작업 우선, 라운드 로빈, 우선순위 스케줄링에서 어떤 프로세스로 CPU를 할당 받는지 정리해보기
🖍 )
1. 선입 선처리 : 준비 큐에 먼저 적재된 순서대로 CPU를 할당 받는다. (FCFS)
2. 최단 작업 우선 : CPU 사용시간이 가장 짧은 프로세스부터 가장 긴 프로세스까지 순차적으로 할당 받는다. (SJF)
3. 라운드 로빈 : 정해진 타임슬라이스만큼씩 프로세스들에게 CPU를 할당하는데, 할당 순서는 준비 큐에 먼저 적재된 순서대로...
4. 우선순위 스케줄링 : 프로세스들에 우선순위를 부여하고 우선순위가 높은 프로세스부터 순차적으로 실행한다.
자세한 내용 확인하러 가기🧚♀️
수정) 준비 큐에 A, B, C, D 순으로 삽입되었다고 가정했을 때, 선입 선처리 스케줄링 알고리즘을 적용하면 어떤 프로세스 순서대로 CPU를 할당 받는지 풀어보기
🖍 )
선입 선처리 스케줄링 알고리즘은 준비 큐에 적재된 순서대로 CPU를 할당 받는다. 고로 삽입된 순서인 A, B, C, D 의 순서로 CPU를 할당 받는다.
이렇게 할당받아 작업을 수행하는 와중에 준비큐에 적재된 프로세스들의 기다리는 시간이 매우 길어질 수 있다. 그런 호위 효과를 해결하기 위해 다양한 스케줄링 알고리즘이 존재한다. (위의 링크를 눌러봐!! 🤭)
9️⃣ 운영체제 시작하기
09-1 운영체제를 알아야 하는 이유
운영체제란
- 자원/시스템 자원 : 프로그램 실행에 있어 마땅히 필요한 요소 (컴퓨터의 네 가지 핵심 부품 포함)
- 실행할 프로그램에 필요한 자원을 할당하고 프로그램이 올바르게 실행되도록 돕는 특별한 프로그램
✅ 응용 프로그램 : 사용자가 특정 목적을 위해 사용하는 일반적인 프로그램
운영체제의 메모리 관리
- 운영체제 또한 메모리에 적재되지만, 매우 특별한 프로그램이므로 항상 컴퓨터가 부팅될 때 메모리 내 커널 영역에 적재된다.
- 응용 프로그램의 경우 메모리내에 사용자 영역에 적재된다.
운영체제의 CPU 관리
- 사용자가 인지하지 못하는 아주 미세한 단위의 시간마다 각종 프로그램을 번갈아 실행 ➡️ 동시에 실행되는 것처럼 느낌
- 어떤 프로그램부터 CPU를 사용하게 할지, 얼마나 오랫동안 CPU를 이용하게 할지 등의 문제를 운영체제가 해결해준다.
운영체제의 입출력장치 관리
- 입출력 장치를 이용하는 응용프로그램의 제어와 입출력 장치 간의 자원을 관리한다.
- 운영체제는 응용 프로그램과 하드웨어 사이에서 응용 프로그램에 필요한 자원을 할당하고, 응용 프로그램이 올바르게 실행되도록 관리하는 역할을 수행한다.
운영체제를 알아야 하는 이유
- 하드웨어를 조작하는 코드를 직접 개발해야한다!! ➡️ 으악!! 👻
- 운영체제는 사용자를 위한 프로그램이 아니다. ➡️ 프로그램을 위한 프로그램 🤔
- 프로그램을 만드는 개발자는 운영체제를 알아야 한다.
- 문제 해결 능력과 관련 : 개발자가 작성한 프로그램이 하드웨어 상에서 어떻게 작동하는지를 파악하는 것은 운영체제 ➡️ 운영체제를 이해함으로써 하드웨어와 프로그램을 더 깊이 이해할 수 있다.
- 운영체제가 알려주는 오류 메세지에 대한 깊은 이해 가능
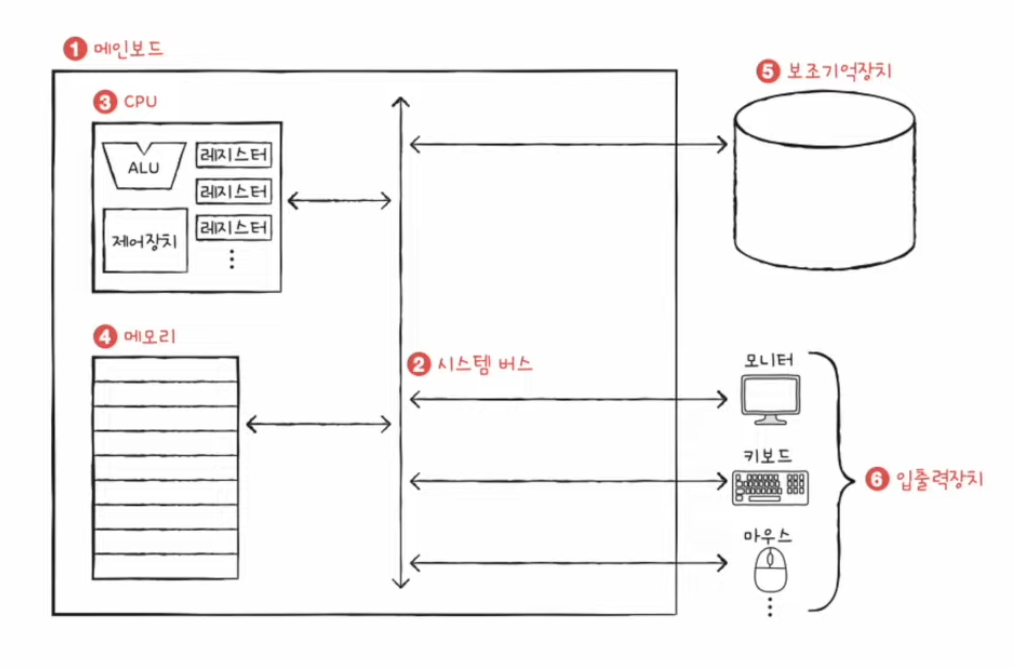
09-2 운영체제의 큰 그림
커널
- 운영체제는 현존하는 프로그램 중 규모가 가장 큰 프로그램 중 하나
- 운영체제가 제공하는 가장 핵심적인 서비스 : 자원에 접근하고 조작하는 기능, 프로그램이 올바르고 안전하게 실행되게 하는 기능
- 운영체제의 핵심 서비스를 담당하는 부분을 커널이라고 한다.
✅ 운영체제에는 속하는데 커널에는 속하지 않는 기능? ➡️ 유저 인터페이스 (UI; User Interface)
사용자와 컴퓨터 간의 통로일 뿐 운영체제의 핵심 기능(커널)은 아님
- 운영체제는 사용자가 실행하는 응용 프로그램이 하드웨어 자원에 직접 접근하는 것을 방지하여 자원을 보호한다.
- 응용 프로그램이 자원에 접근하려면 운영체제에 도움을 요청 (= 운영체제의 코드를 실행) 해야한다.

이중 모드
- CPU가 명령어를 실행하는 모드를 크게 사용자 모드와 커널 모드로 구분하는 방식
- 사용자 모드
- 운영체제 서비스를 제공받을 수 없는 실행 모드
- 커널 영역의 코드를 실행할 수 없는 실행 모드
- 자원 접근 불가
- 커널 모드
- 운영체제의 서비스를 제공받을 수 있는 실행 모드
- 자원 접근을 비롯한 모든 명령어 실행 가능
✅ 플래그 참조 : 슈퍼바이저 플래그 (https://goming0925.tistory.com/16)
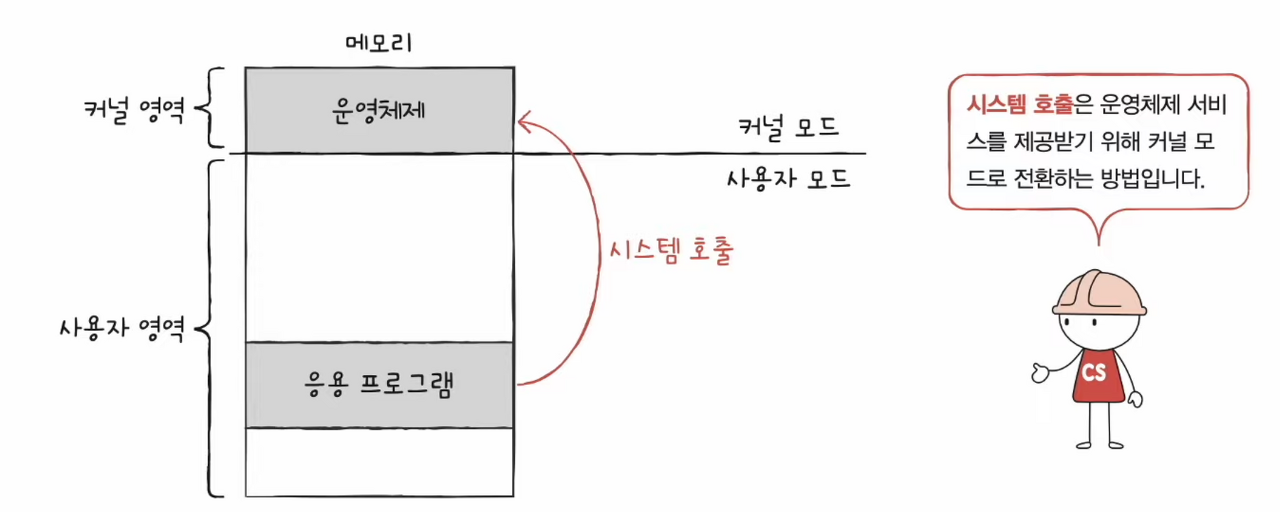
시스템 호출
- 운영체제 서비스를 제공받기 위해 커널 모드로 전환하여 실행하기 위해 호출
- 일종의 소프트웨어 인터럽트
- 시스템 호출이 처리되는 방식은 하드웨어 인터럽트 처리 방식과 유사하다.
운영체제의 핵심 서비스
- 프로세스 관리
- 프로세스 == 실행 중인 프로그램
- 수많은 프로세스들이 동시에 실행된다.
- 윈도우에서 작업 관리자에 출력되는 프로세스!
- 프로세스마다 상태, 상황, 사용하고자 하는 자원이 다르다.
- 동시다발적으로 생성/실행/삭제되는 다양한 프로세스를 일목요연하게 관리한다. ➡️ 프로세스와 스레드, 프로세스 동기화, 교착상태 해결
- 자원 접근 및 할당
- CPU (CPU 스케줄링 : 어떤 프로세스를 먼저, 얼마나 오래 실행할까?)
- 메모리 (페이징, 스와핑, …)
- 입출력장치
- 파일 시스템 관리
- 관련된 정보를 파일이라는 단위로 저장 장치에 보관
- 파일들을 묶어 폴더(디렉터리) 단위로 저장 장치에 보관
✅ 운영체제의 어떤 기법에 의해서 모든 프로세스가 메모리에 올라와 있지 않을 수도 있다?! ➡️ 페이징, 스와핑
🔟 프로세스와 스레드
10-1 프로세스 개요
프로세스
- 실행 중인 프로그램
- 보조기억장치에 저장된 프로그램을 메모리에 적재하고 실행하는 과정 : ‘프로세스 생성 과정’
포그라운드 프로세스 (foreground process)
- 사용자가 볼 수 있는 공간에서 실행되는 프로세스
백그라운드 프로세스 (background process)
- 사용자가 볼 수 없는 공간에서 실행되는 프로세스
- 사용자와 직접 상호작용이 가능한 백그라운드 프로세스
- 사용자와 상호작용하지 않고 그저 정해진 일만 수행하는 프로세스 : 데몬(daemon), 서비스(service)
프로세스 제어 블록
- 모든 프로세스는 실행을 위해 CPU가 필요하다. 하지만 CPU의 자원은 한정되어있다.
- 프로세스들은 돌아가며 한정된 시간 만큼만 CPU 이용
- 자신의 차례에 정해진 시간만큼 CPU 이용한다.
- 타이머 인터럽트가 발생하면 차례를 양보한다.
- 빠르게 번갈아 수행되는 프로세스들을 관리하기 위해 사용되는 자료구조가 프로세스 제어 블록 (이하 PCB)
- 프로세스 관련 정보를 저장하는 자료 구조
- 마치 상품에 달린 태그와 같은 정보
- 프로세스 생성 시 커널 영역에 생성, 종료 시 폐기
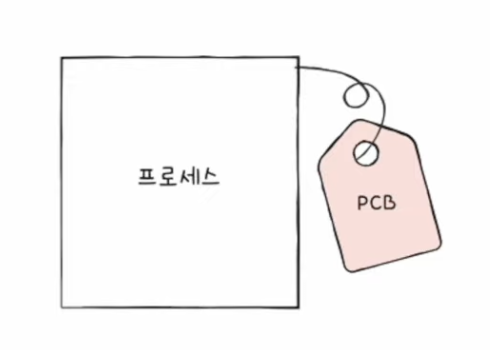
- PCB에 담기는 대표적인 정보 (운영체제마다 차이가 있음)
- 프로세스 ID (=PID)
- 레지스터 값
- 프로세스 상태
- CPU 스케줄링 정보
- 메모리 정보
- 사용한 파일과 입출력장치 정보
프로세스 ID
- 특정 프로세스를 식별하기 위해 부여하는 고유한 번호 (학교의 학번, 회사의 사번)
레지스터 값
- 프로세스는 자신의 실행 차례가 오면 이전까지 사용한 레지스터 중간 값을 모두 복원 ➡️ 실행 재개를 위한 값
- 프로그램 카운터, 스택 포인터 … 등
프로세스 상태
- 입출력 장치를 사용하기 위해 기다리는 상태
- CPU를 사용하기 위해 기다리는 상태
- CPU를 이용 중인 상태
CPU 스케줄링 정보
- 프로세스가 언제, 어떤 순서로 CPU를 할당받을지에 대한 정보
메모리 관리 정보
- 프로세스가 어느 주소에 저장되어 있는지에 대한 정보
- 페이지 테이블 정보 (지금으로서는 ‘메모리 주소를 알 수 있는 정보가 담기는구나’ 라고 이해)
사용한 파일과 입출력장치 정보
- 할당된 입출력장치, 사용 중인(열린) 파일의 정보
문맥 교환 (Context switching)
- 한 프로세스 (예시 : 프로세스 A)에서 다른 프로세스 (예시 : 프로세스B)로 실행 순서가 넘어가면 어떤 작업이 이루어지는지?
- 기존에 실행되던 프로세스 A는 지금까지의 중간 정보를 백업해야한다.
- 뒤이어 실행할 프로세스 B의 문맥을 복구 ➡️ 자연스럽게 실행 중인 프로세스가 바뀜
- 이처럼 기존의 실행 중인 프로세스 문맥을 백업하고, 새로운 프로세스 실행을 위해 문맥을 복구하는 과정을 문맥 교환(context switching) 이라 한다.
- 여러 프로세스가 끊임없이 빠르게 번갈아 가며 실행되는 원리이다.
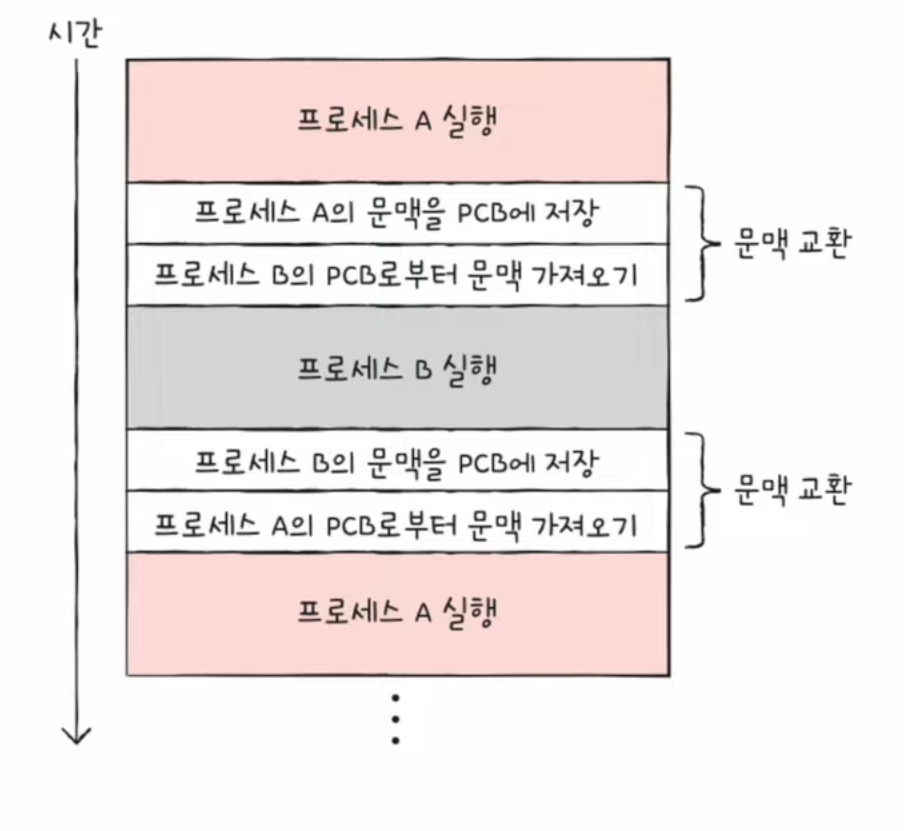
문맥(context)
- 프로그램 카운터 등 각종 레지스터 값, 메모리 정보, 열었던 파일, 사용한 입출력장치 등
- 이러한 중간 정보를 문맥(context)라고 한다.
- 다음 차례가 왔을 때 실행을 재개하기 위한 정보이다.
- 실행 문맥을 백업해두면 언제든 해당 프로세스의 실행을 재개할 수 있다.
✅ PCB는 커널영역에서 프로세스를 관리하기 위한 자료 구조 ➡️ 사용자 영역에서는?
프로세스의 메모리 영역
- 사용자 영역에 저장되는 프로세스는 크게 코드 영역 (=텍스트 영역), 데이터 영역, 힙 영역, 스택 영역 4개이다.
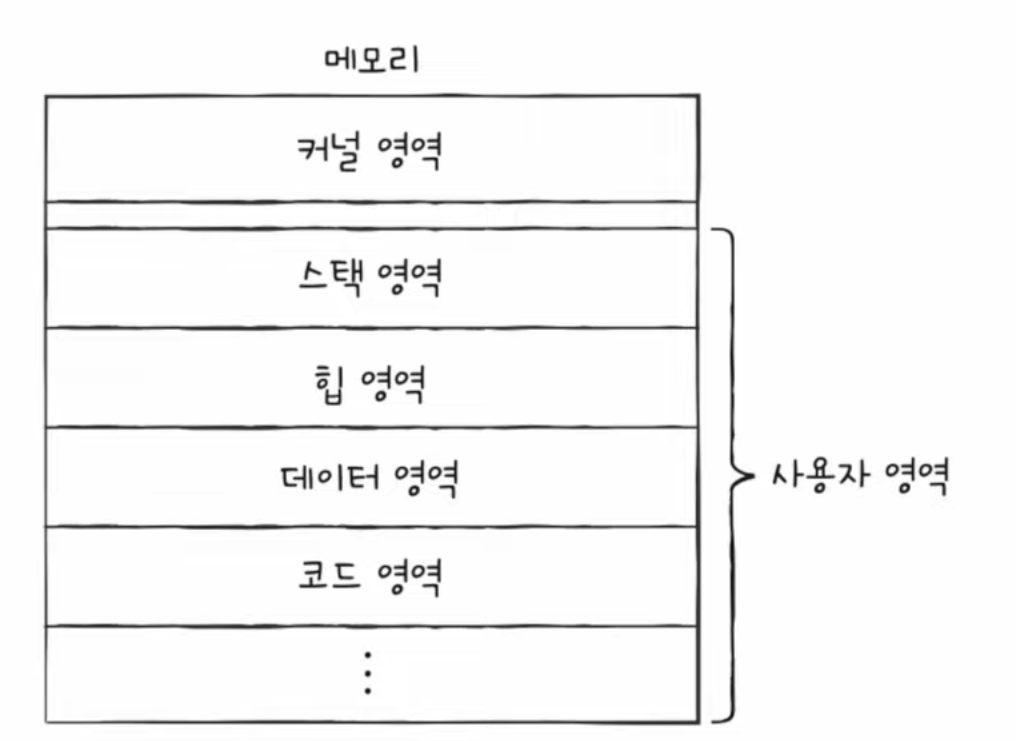
코드 영역 (= 텍스트 영역)
- 실행할 수 있는 코드, 기계어로 이루어진 명령어 저장
- 데이터가 아닌 CPU가 실행할 명령어가 담기기에 쓰기가 금지된 영역 (일반적으로 read-only)
데이터 영역
- 잠깐 썼다가 없앨 데이터가 아닌 프로그램이 실행되는 동안 유지할 데이터 저장
- 예시 : 전역 변수
힙 영역
- 프로그램을 만드는 사용자, 즉 프로그래머가 직접 할당할 수 있는 저장공간
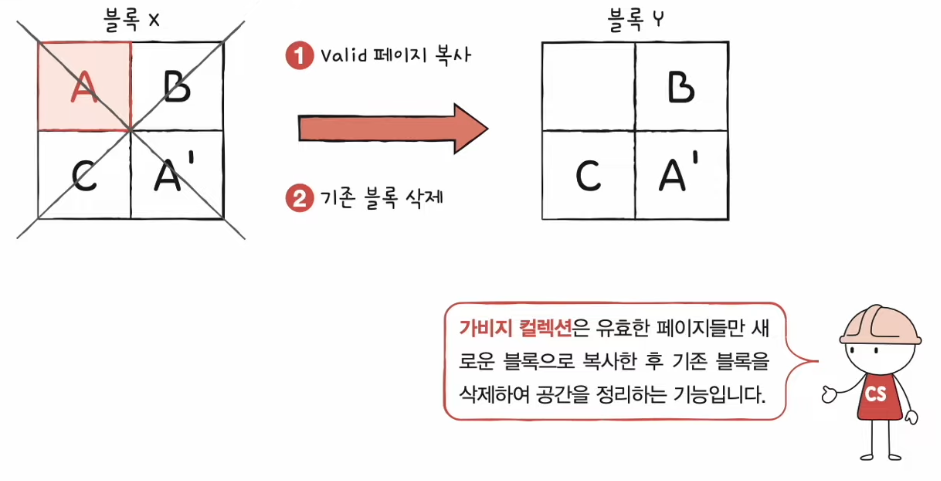
- 프로그래밍에서 메모리 공간을 힙 영역으로 할당했다면 다시 반환되어야 함 ➡️ 프로그래밍 언어가 알아서 해주는 경우가 있음 : 가비지 컬렉션
- 메모리 공간을 반환하지 않는다면 메모리 내에 계속 남아 메모리 낭비를 초래 ➡️메모리 누수 (Memory leak)
스택 영역
- 데이터가 일시적으로 저장되는 공간
- (데이터 영역에 담기는 값과는 달리) 잠깐 쓰다가 마는 값들이 저장되는 공간
- 예시 : 매개 변수, 지역 변수
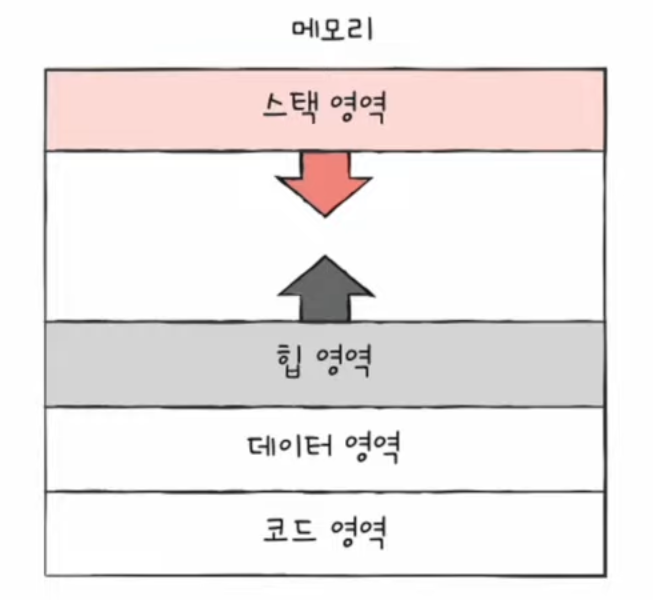
✅ 정적 할당 영역 : 코드 영역과 데이터 영역은 크기가 변하지 않는다. 그래서 코드 영역과 데이터 영역을 ‘크기가 고정된 영역’이라는 점에서 정적 할당 영역이라고도 부른다.
✅ 동적 할당 영역 : 힙 영역과 스택 영역은 프로세스 실행 과정에서 그 크기가 변할 수 있는 영역이다.
✅ 일반적으로 힙 영역은 메모리의 낮은 주소에서 높은 주소로 할당하고
스택 영역은 메모리의 높은 주소에서 낮은 주소로 할당하여 데이터가 쌓여도 할당되는 주소가 겹칠 일이 없게 한다.
10-2 프로세스 상태와 계층 구조
프로세스 상태
- 대부분의 운영체제에서 사용하는 프로세스 상태 (차이가 있을 수 있음)
- 생성 상태 (new)
- 이제 막 메모리에 적재되어 PCB를 할당 받은 상태
- 준비가 완료되었다면 준비 상태로 변경한다.
- 준비 상태 (ready)
- 당장이라도 CPU를 할당 받아 실행할 수 있지만 자신의 차례가 아니기에 기다리는 상태
- 자신의 차례가 된다면 실행 상태로 변경한다. (=디스패치)
- 실행 상태 (running)
- CPU를 할당 받아 실행 중인 상태
- 할당된 시간을 모두 사용 시 (타이머 인터럽트 발생 시) 준비 상태로 되돌아감
- 실행 도중 입출력장치를 사용하면 입출력 작업이 끝날 때까지 대기 상태로 변경됨 (입출력 인터럽트를 받을 때까지)
- 대기 상태 (blocked)
- 프로세스가 실행 도중 입출력장치를 사용하는 경우
- 입출력 작업은 CPU에 비해 느리기에 이 경우 대기 상태로 접어듬
- 입출력 작업이 끝나면 (입출력 완료 인터럽트를 받으면) 준비 상태로 되돌아감
- 종료 상태 (terminated)
- 프로세스가 종료된 상태
- PCB, 프로세스의 메모리 영역 정리
프로세스 상태 다이어그램
프로세스 계층 구조
- 프로스 실행 도중 (시스템 호출을 통해) 다른 프로세스 생성 가능
- 새 프로세스를 생성한 프로세스 : 부모 프로세스
- 부모 프로세스에 의해 생성된 프로세스 : 자식 프로세스
- 부모 프로세스와 자식 프로세스는 별개의 프로세스이므로 각기 다른 PID를 가짐
- 일부 운영체제에서는 자식 프로세스 PCB에 부모 프로세스 PID(PPID)를 명시하기도 한다.
- 자식 프로세스는 또 다른 자식 프로세스를 낳을 수 있다. (반복) ➡️ 프로세스의 계층적인 구조 생성
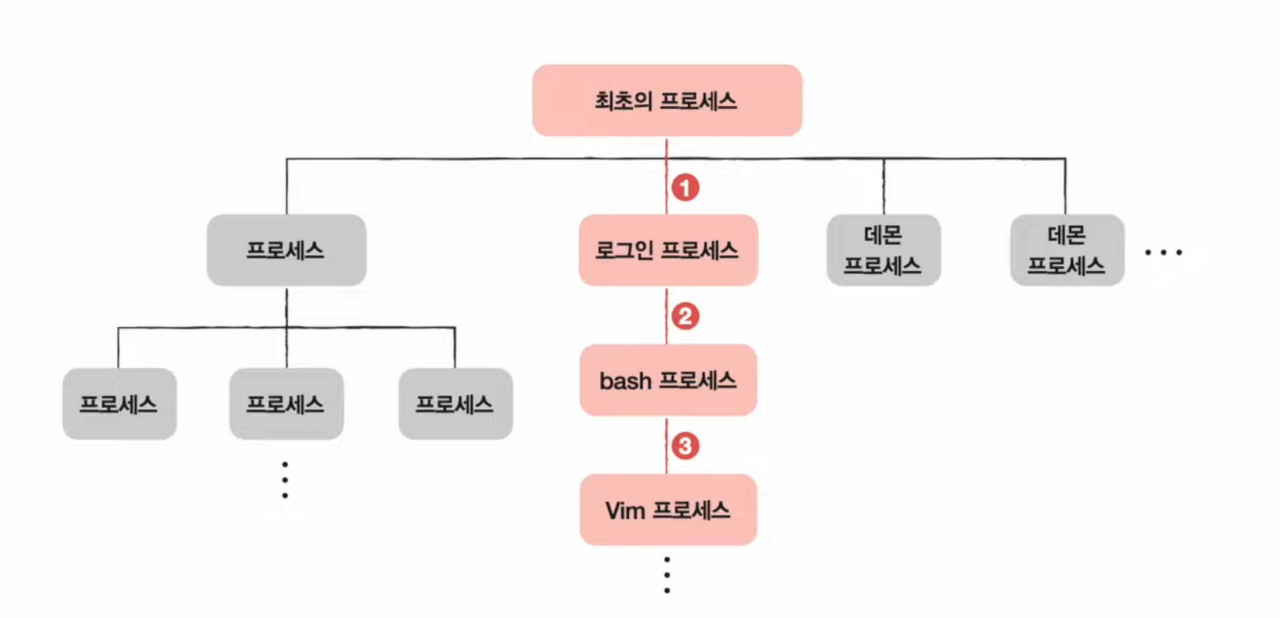
✅ 데몬이나 서비스 또한 최초 프로세스의 자식 프로세스이다.
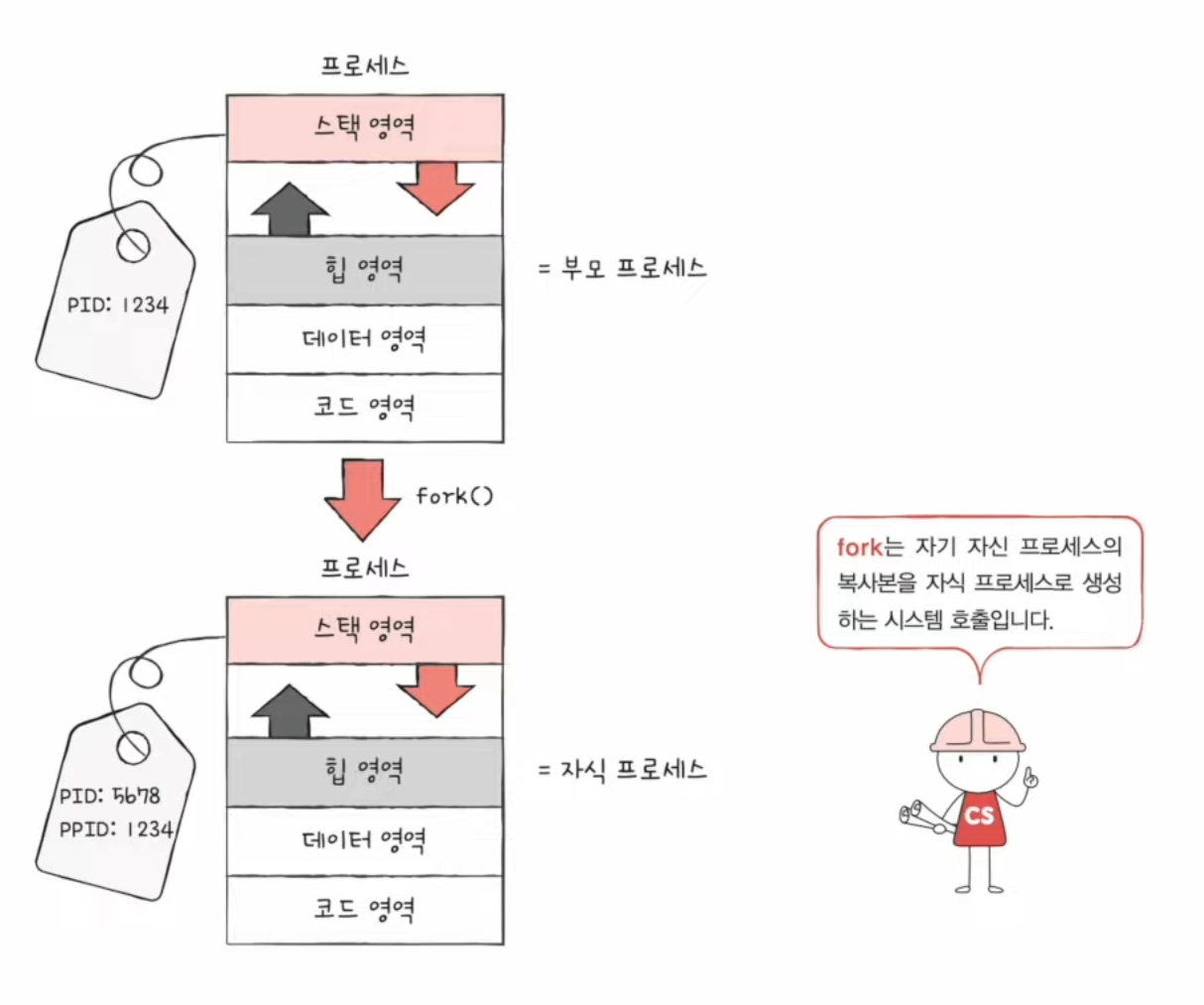
프로세스 생성 기법 (Windows 운영체제와는 큰 관련이 없다)
- 부모 프로세스를 통해 생성된 자식 프로세스들은 복제와 옷 갈아입기를 통해 실행된다.
- 부모 프로세스는 fork 시스템 호출을 통해 자신의 복사본을 자식 프로세스로 생성
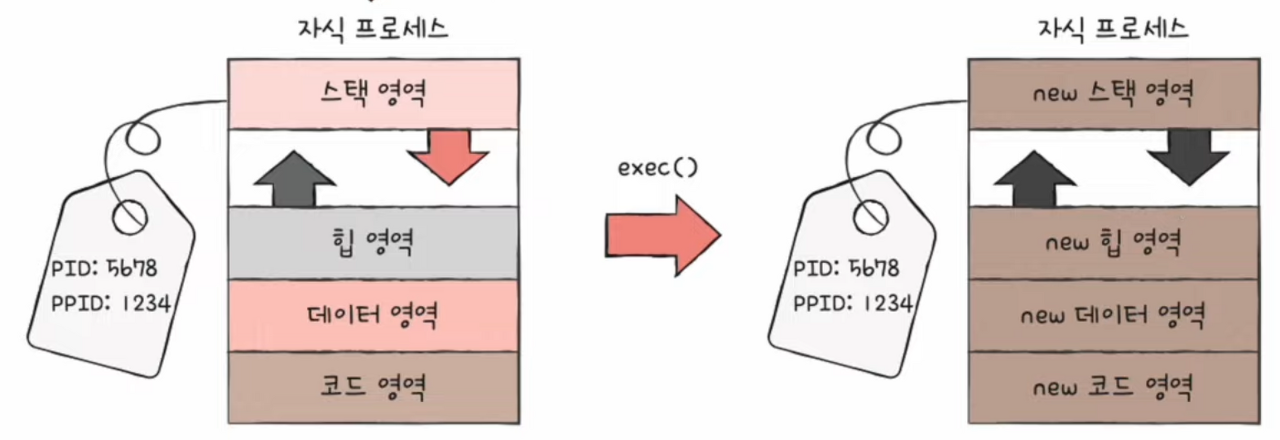
- 자식 프로세스는 exec 시스템 호출을 통해 자신의 메모리 공간을 다른 프로그램으로 교체
fork 시스템 호출
- fork 시스템 호출을 통해 자신의 복사본을 자식 프로세스로써 생성한다.
- 복사본( =자식 프로세스) 생성 (엄연히 다른 프로세스이기에 PID가 다름)
- 부모 프로세스의 자원 상속
exec 시스템 호출
- 메모리 공간을 새로운 프로그램으로 덮어쓰기
- 코드/데이터 영역은 실행할 프로그램 내용으로 바뀌고 나머지 영역은 초기화
10-3 스레드
스레드
- 스레드(thread)는 프로세스를 구성하는 실행 흐름의 단위
- 하나의 프로세스는 하나 이상의 스레드를 가질 수 있다.
✅ 단일 스레드 프로세스 : 실행의 흐름 단위가 하나인 프로세스
✅ 멀티 스레드 프로세스 : 실행 흐름이 여러 개인 프로세스 ➡️ 프로세스를 이루는 여러 명령어를 동시 실행 가능
스레드의 구성 요소
- 스레드ID, 프로그램 카운터를 비롯한 레지스터 값, 스택 등
- 실행에 필요한 최소한의 정보를 가지고 있다.
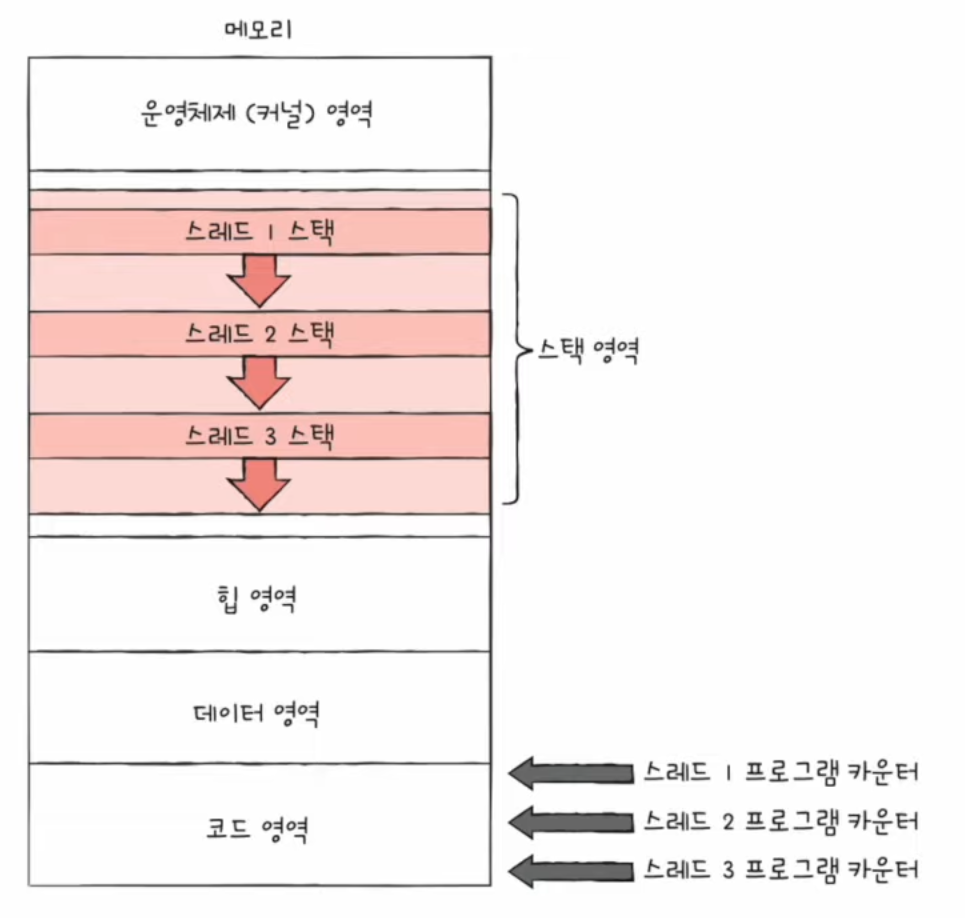
- 실행에 필요한 최소한의 정보를 가지고 있지만 프로세스의 자원을 공유한다.
- 프로세스의 코드 영역과 데이터 영역을 스레드가 이용하기 때문
✅ 프로세스가 실행되는 프로그램이라면, 스레드는 프로세스를 구성하는 실행의 흐름 단위
➡️ 실제로 최근 많은 운영체제에서 CPU에 처리할 작업을 전달할 때 프로세스가 아닌 스레드 단위로 전달한다.
멀티 프로세스와 멀티 스레드
- 동일한 작업을 수행하는 : 단일 스레드 프로세스 여러개 vs 하나의 프로세스를 여러 스레드로 실행
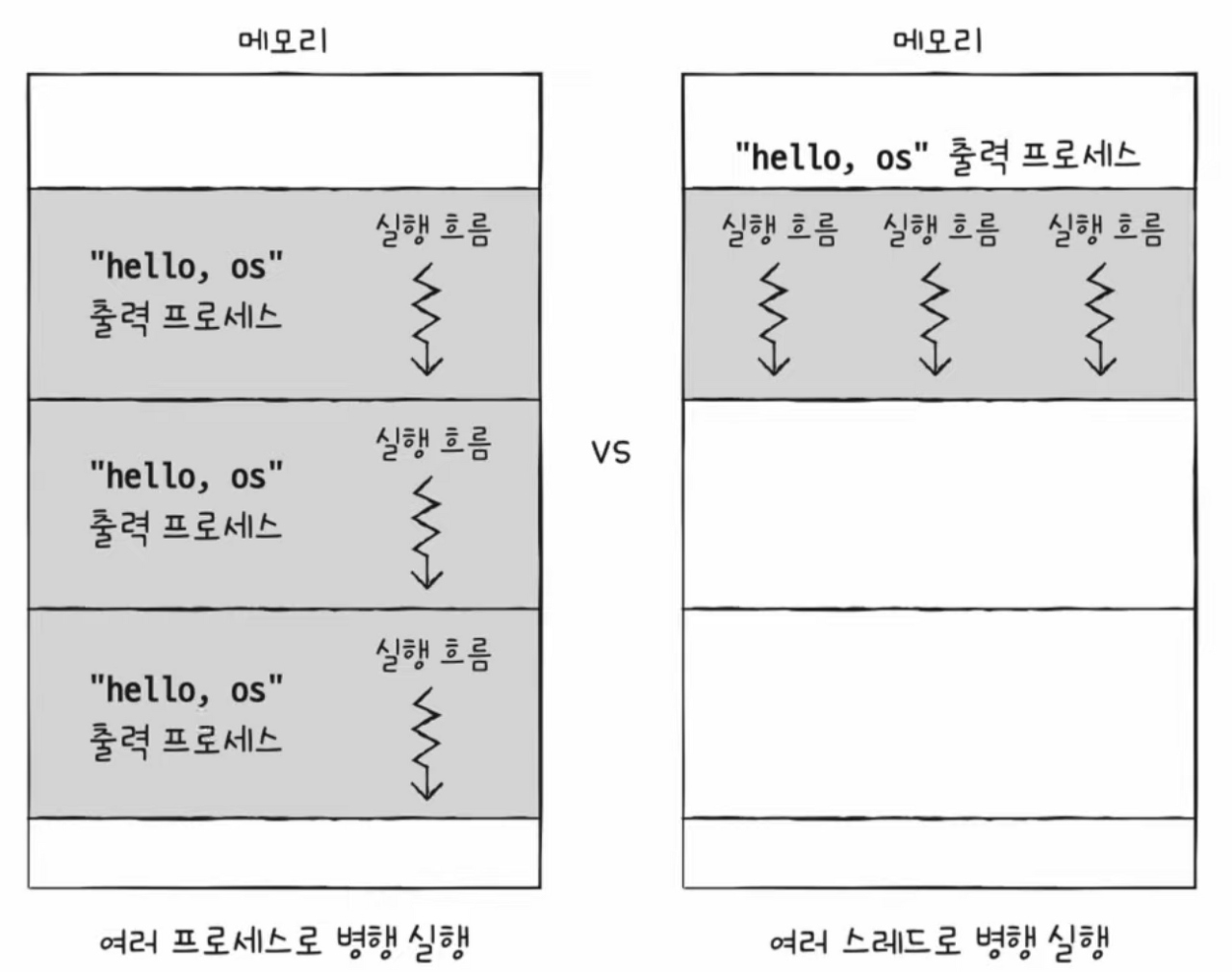
- 둘 다 결과적으로 3번의 실행이 발생하지만 큰 차이가 있다.
- 프로세스끼리는 기본적으로 자원을 공유하지 않음 vs 스레드끼리는 같은 프로세스 내의 자원을 공유함
멀티 프로세스의 경우
- 프로세스를 fork 할 경우 코드/데이터/힙 영역 등 모든 자원이 복제되어 저장됨
- 저장된 메모리 주소를 제외하면 모든 것이 동일한 프로세스 두 개가 통째로 메모리에 적재되는 형태
- 중복되는 자원 ➡️ 자원의 낭비
- 자원을 공유하지 않는다. ➡️ 남남처럼 독립적으로 실행된다. ➡️ 자원의 낭비
✅ 프로세스 간에도 자원을 주고 받을 수 있다. : 프로세스 간 통신 (IPC)
파일을 통한 프로세스 간 통신, 공유 메모리를 통한 프로세스 간 통신 등이 존재함
멀티 스레드의 경우
- 스레드들은 각기 다른 스레드 ID, (별도의 실행을 위해 꼭 필요한) 프로그램 카운터 값을 포함한 레지스터 값, 스택을 가질 뿐 프로세스가 가지는 자원을 공유한다.
- 자원을 공유한다. ➡️ 협력과 통신에 유리하다. ➡️ 공유되는 자원으로 문제가 될 수도 있다.
1️⃣1️⃣ CPU 스케줄링
11-1 CPU 스케줄링 개요
CPU 스케줄링
- 운영체제가 프로세스들에게 공정하고 합리적으로 CPU 자원을 배분하는 것
가장 공정한 CPU 스케줄링?
CPU를 사용하고 싶어하는 프로세스들이 차례로 돌아가면서 사용- 빠르게 처리 되어야 하는 프로세스가 존재한다 (= 프로세스마다 우선순위가 다르다)
- 입출력 작업이 많은 프로세스 (= 입출력 집중 프로세스)의 우선순위는 CPU 작업이 많은 프로세스 (= CPU 집중 프로세스)의 우선순위보다 높다.
- 입출력 집중 프로세스는 대기 상태가 많기 때문에 먼저 처리하고 대기 상태일때 CPU 집중 프로세스를 처리하면 효율적이다.
✅ 입출력 집중 프로세스 : I/O bound process, CPU 집중 프로세스 : CPU bound process
프로세스 우선순위(priority)
- PCB에 적힌 우선순위를 기준으로 먼저 처리할 프로세스를 결정한다.
- 자연스럽게 우선순위가 높은 프로세스는 더 빨리, 더 자주 실행된다.
스케줄링 큐
- 매번 모든 프로세스의 PCB를 검색해서 우선순위를 확인하는 것은 비효율적이다.
- CPU 스케줄링 큐에 프로세스들을 줄 세워둔다.
- 스케줄링에서의 큐는 반드시 FIFO(선입선출) 방식일 필요는 없다. (중간에 추가되고 바뀔 수도 있으니)
- 같은 큐 내에서도 우선순위에 따라 처리 된다.
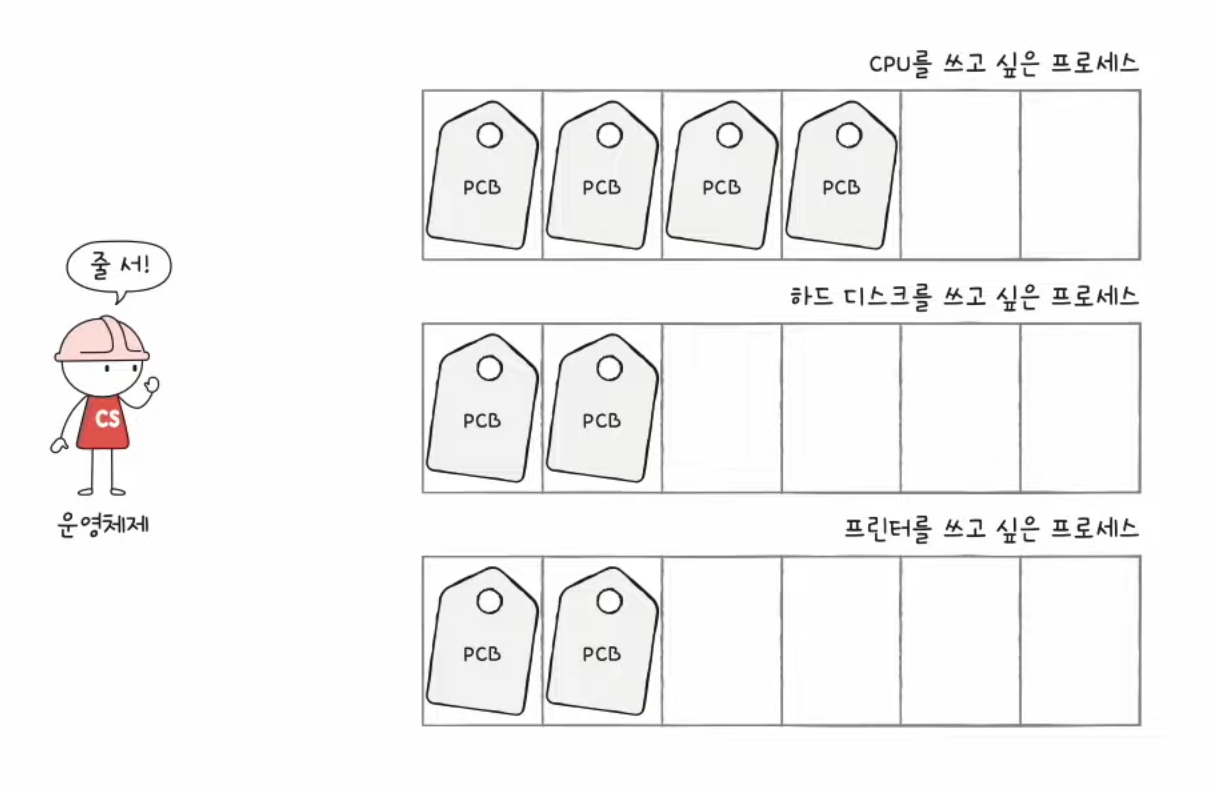
준비 큐
- CPU를 이용하기 위해 기다리는 줄
대기 큐
- 입출력장치를 이용하기 위해 기다리는 줄
- 입출력장치별로 큐가 존재하여 같은 장치를 요구한 프로세스들을 같은 큐로 묶어서 대기
선점형 스케줄링 (preemptive scheduling)
- 프로세스가 CPU를 비롯한 자원을 사용하고 있더라도 운영체제가 프로세스로부터 자원을 강제로 빼앗아 다른 프로세스에게 할당할 수 있는 스케줄링 방식
- 장점 : 어느 하나의 프로세스가 자원 사용을 독점을 막고 프로세스들에 골고루 자원을 배분할 수 있다.
- 단점 : 그만큼 문맥 교환 과정에서 오버헤드가 발생할 수 있다.
비선점형 스케줄링 (non-preemptive scheduling)
- 하나의 프로세스가 자원을 사용하고 있다면 그 프로세스가 종료되거나 스스로 대기 상태에 접어들기 전까지 다른 프로세스가 끼어들 수 없는 스케줄링
- 장점 : 문맥 교환에서 발생하는 오버헤드가 선점형 스케줄링보다 적다.
- 단점 : 모든 프로세스가 골고루 자원을 이용하기 어렵다.
11-2 CPU 스케줄링 알고리즘
CPU 스케줄링 알고리즘은 다양하고 운영체제마다 다르다.
CPU 스케줄링의 종류 (일반적인 전공서 기준의 기본)
- 선입 선처리 스케줄링
- 최단 작업 우선 스케줄링
- 라운드 로빈 스케줄링
- 최소 잔여 시간 우선 스케줄링
- 우선순위 스케줄링
- 다단계 큐 스케줄링
- 다단계 피드백 큐 스케줄링
선입 선처리 스케줄링
- FCFS (First Come First Served) 스케줄링
- 단순히 준비 큐에 삽입된 순서대로 처리하는 비선점 스케줄링
- 먼저 CPU를 요청한 프로세스부터 CPU 할당
- 단점 : 프로세스들이 기다리는 시간이 매우 길어질 수 있다는 부작용 (=호위 효과)
최단 작업 우선 스케줄링
- SJF (Shortest Job First) 스케줄링
- 선입 선처리 스케줄링에서 호위 효과를 방지하는 스케줄링
- CPU 사용이 긴 프로세스는 나중에 실행, CPU 사용 시간이 짧은 프로세스는 먼저 실행
- CPU 사용 시간이 가장 짧은 프로세스부터 처리하는 스케줄링 방식
- 선점형/비선점형으로 구현될 수 있고 기본적으론 비선점형으로 분류됨
라운드 로빈 스케줄링
- RR (Round Robin) 스케줄링
- 선입 선처리 스케줄링 + 타임 슬라이스 (time slice)
- 타임 슬라이스 : 각 프로세스가 CPU를 사용할 수 있는 정해진 시간
- 정해진 타임 슬라이스만큼의 시간 동안 돌아가며 CPU를 이용하는 선점형 스케줄링
- 큐에 삽입된 프로세스들은 순서대로 CPU를 이용하되 정해진 시간만큼만 이용한다.
- 정해진 시간을 모두 사용하였음에도 아직 프로세스가 완료되지 않았다면 다시 큐의 맨 뒤에 삽입 (문맥교환)
- 타임 슬라이스의 크기가 중요하다. (너무 크면 선입 선처리 스케줄링과 다를 바가 없고, 너무 작으면 문맥 교환에 발생하는 비용이 커진다.)
최소 잔여 시간 우선 스케줄링
- SRT (Shortest Remaining Time) 스케줄링
- 최단 작업 우선 스케줄링 + 라운드 로빈 스케줄링
- 최단 작업 우선 스케줄링 : 작업 시간이 짧은 프로세스부터 처리하는 스케줄링 알고리즘
- 라운드 로빈 스케줄링 : 정해진 타임 슬라이스만큼 돌아가며 사용하는 스케줄링 알고리즘
- 정해진 시간만큼 CPU를 이용하되, 다음으로 CPU를 사용할 프로세스는 남은 작업 시간이 가장 적은 프로세스로 선택한다.
우선순위 스케줄링
- 프로세스들에 우선순위를 부여하고, 우선순위 높은 프로세스부터 실행
- 우선순위가 같은 프로세스들은 선입 선처리로 스케줄링
- 최단 작업 우선 스케줄링, 최소 잔여 시간 스케줄링은 넓은 의미에서 우선순위 스케줄링에 일종이다.
- 우선순위 스케줄링의 근본적인 문제점, 기아(starvation) 현상
- 우선순위 높은 프로세스만 주구장창 실행
- 우선순위 낮은 프로세스는 (준비 큐에 먼저 삽입되었음에도 불구하고) 실행 연기
- 기아현상을 방지하기 위한 기법 : 에이징(aging)
- 오랫동안 대기한 프로세스의 우선순위를 점차 높이는 방식
- 대기 중인 프로세스의 우선순위를 마치 나이 먹듯 점차 증가시키는 방법
- 즉, 우선순위가 낮아도 언젠가는 우선순위가 높아진다.
다단계 큐 스케줄링
- Multilevel queue 스케줄링
- 우선순위 스케줄링의 발전된 형태
- 우선순위별로 준비 큐를 여러 개 사용하는 스케줄링 방식
- 우선순위가 가장 높은 큐에 있는 프로세스를 먼저 처리
- 우선순위가 가장 높은 큐가 비어 있으면 그 다음 우선순위 큐에 있는 프로세스 처리
- 다단계 큐 스케줄링에서는 기본적으로 큐 간의 이동이 불가하다.
- 우선순위가 낮은 프로세스는 계속해서 실행이 연기 될 수 있다.
- 준비 큐 간에 이동이 불가능하기 때문에 기아현상이 발생할 수 있다.
✅ 프로세스 유형별로 우선순위를 구분하여 실행하는 것이 편리해진다. ➡️ 준비 큐별로 스케줄링 방식을 다양하게 적용할 수 있다.
다단계 피드백 큐 스케줄링
- Multilevel feedback queue 스케줄링
- 다단계 큐 스케줄링의 발전된 형태
- 큐 간의 이동이 가능한 다단계 큐 스케줄링
- 자연스럽게 CPU 집중 프로세스의 우선순위가 상대적으로 낮아지고 입출력 집중 프로세스의 우선순위는 상대적으로 높아진다.
- 타임슬라이스에서 CPU 작업이 끝나지 않으면(CPU 작업이 많으면 = CPU 집중 프로세스) 다음 우선순위 큐로 이동…
- 다단계 피드백 큐 스케줄링에서도 에이징 기법을 적용할 수 있다.
- 어떤 프로세스의 CPU 시간이 길면 우선순위가 낮아지고, 어떤 프로세스가 낮은 우선순위 큐에서 너무 오래 기다리면 우선순위를 높이는 방식
- 가장 일반적인 CPU 스케줄링 방식으로 알려져있음
'혼공컴운' 카테고리의 다른 글
| 혼자 공부하는 컴퓨터 구조+운영체제 6주차 (14~15) (0) | 2023.02.19 |
|---|---|
| 혼자 공부하는 컴퓨터 구조+운영체제 5주차 (12~13) (0) | 2023.02.12 |
| 혼자 공부하는 컴퓨터 구조+운영체제 3주차 (6~8) (0) | 2023.01.24 |
| 혼자 공부하는 컴퓨터 구조+운영체제 2주차 (4~5) (0) | 2023.01.15 |
| 혼자 공부하는 컴퓨터 구조+운영체제 1주차 (1~3) (0) | 2023.01.08 |