
📃 기본 미션1
p.185, 확인 문제 3번 ) 다음 설명을 읽고 SRAM에 대한 설명인지 DRAM에 대한 설명인지 쓰세요.
보기 : SRAM, DRAM
① 주로 캐시 메모리로 활용됩니다.
② 주로 주기억장치로 활용됩니다.
③ 대용량화하기 유리합니다.
④ 집적도가 상대적으로 낮습니다.
🖍 )
① = SRAM
② = DRAM
③ = DRAM
④ = SRAM
📃 기본 미션2
p.205, 확인 문제 1번 ) 다음 보기에 있는 저장 장치들로 저장 장치 계층 구조 도식도를 채우세요.
보기 : 메모리, 보조기억장치, 캐시 메모리, 레지스터
🖍 )
① = 레지스터
② = 캐시 메모리
③ = 메모리
④ = 보조기억장치
📃 선택 미션
RAID의 정의와 종류를 간단히 정리해보기
🖍 )
Chapter 6️⃣
06-1 RAM의 특징과 종류
RAM
- 실행할 프로그램의 명령어와 데이터가 저장됨
휘발성 저장 장치
- 전원을 끄면 저장된 명령어와 데이터가 모두 날아가는 저장 장치
- RAM이 대표적이다.
- CPU가 ‘실행할 대상’을 저장한다.
비 휘발성 저장 장치
- 전원이 꺼져도 저장된 내용이 유지되는 저장 장치
- 하드 디스크, SSD, CD-ROM, USB 메모리 등이 있다.
- CPU가 직접 접근하지 못한다.
- 작업 결과물과 같은 ‘보관할 대상’을 저장한다.
✅ RAM 용량이 크다면 CPU가 실행하고자 하는 프로그램을 RAM에 많이 저장 할 수 있으며, 보조 기억장치로의 접근이 최소화 되어 시간을 절약할 수 있다.
DRAM (Dynamic RAM)
- 저장된 데이터가 동적으로 사라지는 RAM
- 데이터 소멸을 막기 위해 주기적으로 재활성화 해야한다.
- 일반적으로 메모리로써 사용하는 RAM
- 소비 전력이 비교적 낮고, 용량 대비 저렴, 집적도가 높다
✅ 집적도가 높다 : 더 작고 빽빽하게 만들 수 있다.
SRAM (Static RAM)
- 저장된 데이터가 정적인 (사라지지 않는) RAM
- 전원 공급이 멈추면 저장된 데이터가 날아가긴 한다.
- DRAM보다 일반적으로 더 빠름
- 일반적으로 캐시 메모리에서 사용되는 RAM
- 상대적으로 소비전력이 높고, 가격이 높고, 집적도가 낮다
- 대용량으로 설계할 필요는 없으나 빨라야 하는 장치에 사용한다.
| DRAM | SRAM | |
| 재충전 | 필요함 | 필요 없음 |
| 속도 | 느림 | 빠름 |
| 가격 | 저렴함 | 비쌈 |
| 집적도 | 높음 | 낮음 |
| 소비 전력 | 적음 | 높음 |
| 사용 용도 | 주기억장치(RAM) | 캐시 메모리 |
SDRAM (Synchronous DRAM)
- 발전된 형태의 DRAM
- 클럭 신호와 동기화된 DRAM
- 클럭 신호와 동기화 되어있다는 의미는 CPU와 정보를 주고 받을 수 있다는 의미이다.
DDR SDRAM(Double Data Rate SDRAM)
- 발전된 형태의 SDRAM
- 최근 가장 대중적으로 사용하는 RAM
- 대역폭을 넓혀 속도를 빠르게 만든 SDRAM
- 비유적으로 대역폭은 데이터를 주고 받는 길의 너비
06-2 메모리의 주소 공간
CPU와 실행 중인 프로그램은 메모리 몇 번지에 무엇이 저장되어 있는지 다 알지 못한다.
메모리에 저장된 값들은 시시각각 변한다
물리 주소
- 메모리 하드웨어가 사용하는 주소
- 메모리 입장에서 바라본 주소
- 말 그대로 정보가 실제로 저장된 하드웨어상의 주소
논리 주소
- CPU와 실행 중인 프로그램이 사용하는 주소
- CPU와 실행 중인 프로그램 입장에서 바라본 주소
- 실행 중인 프로그램 각각에게 부여된 0번지부터 시작하는 주소
- 새롭게 실행되는 프로그램은 새롭게 메모리에 적재
- 실행이 끝난 프로그램은 메모리에서 삭제
- 같은 프로그램을 실행하더라도 실행할 때마다 적재되는 주소는 달라짐
결국엔 논리 주소를 물리 주소로 변환해야 한다. → 실질적인 메모리 접근을 위해서
MMU (메모리 관리 장치)라는 하드웨어에 의해 변환
MMU는 논리 주소와 베이스 레지스터 값을 더하여 논리 주소를 물리 주소로 변환한다.
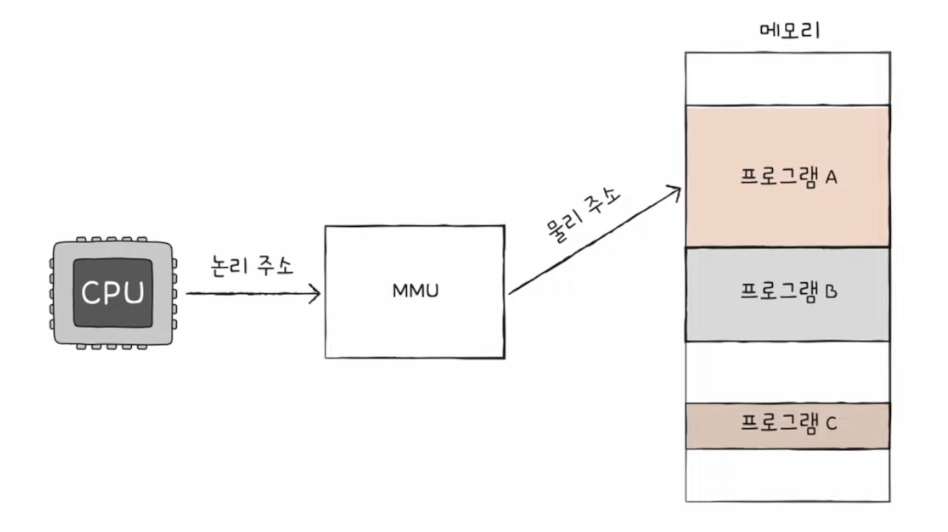
✅ 베이스 레지스터 : 프로그램의 기준 주소, 프로그램의 시작 주소(물리 주소)
2주차 강의 중 레지스터 항목을 참고 (https://goming0925.tistory.com/16)
정리하면,
베이스 레지스터는 프로그램의 가장 작은 물리 주소, 프로그램의 첫 물리 주소를 저장한다.
논리 주소는 프로그램의 시작점으로부터 떨어진 거리이다.
메모리 보호 기법
- 가정 : 본인 프로그램 논리 주소번지를 벗어나는 값의 데이터를 변경한다 ➡️ 타 프로그램의 데이터에 변화가 생긴다 ➡️ 으악☠️
- 논리 주소 범위를 벗어나는 명령어 실행을 방지하고 실행 중인 프로그램이 다른 프로그램에 영향을 받지 않도록 보호할 방법이 필요 : 한계 레지스터
- CPU는 메모리에 접근하지 전에 접근하고자 하는 논리 주소가 한계 레지스터보다 작은지를 항상 검사한다.
- 실행 중인 프로그램의 독립적인 실행 공간을 확보
- 하나의 프로그램이 다른 프로그램을 침범하지 못하게 보호
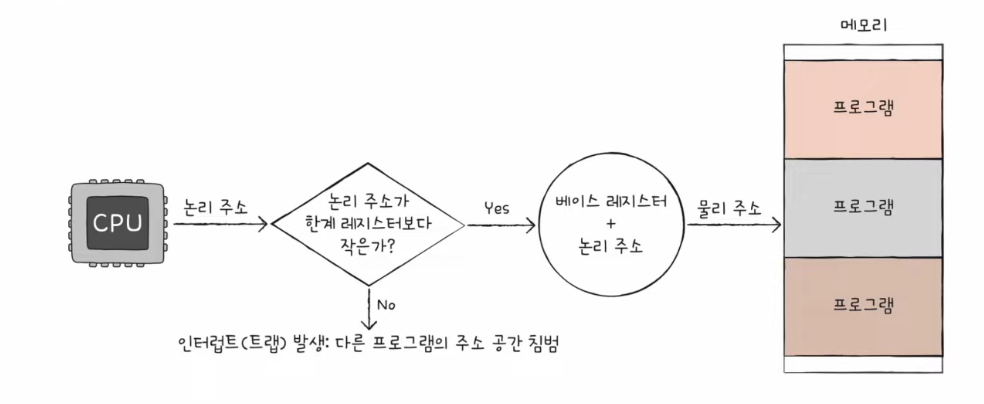
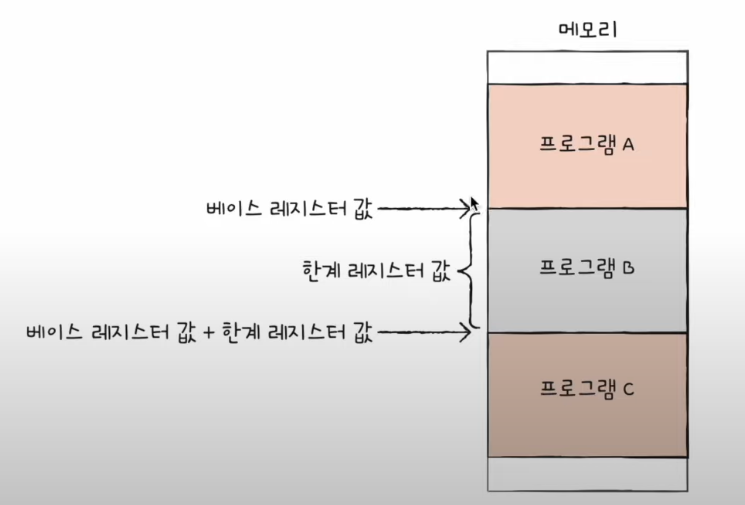
한계 레지스터
- 프로그램의 영역을 침범할 수 있는 명령어의 실행을 막을때 사용
- 베이스 레지스터가 실행 중인 프로그램의 가장 작은 물리 주소를 저장한다면, 한계 레지스터는 논리 주소의 최대 크기를 저장
- 베이스 레지스터 값 ≤ 프로그램의 물리 주소 범위 < 베이스 레지스터 + 한계 레지스터 값
06-3 캐시 메모리
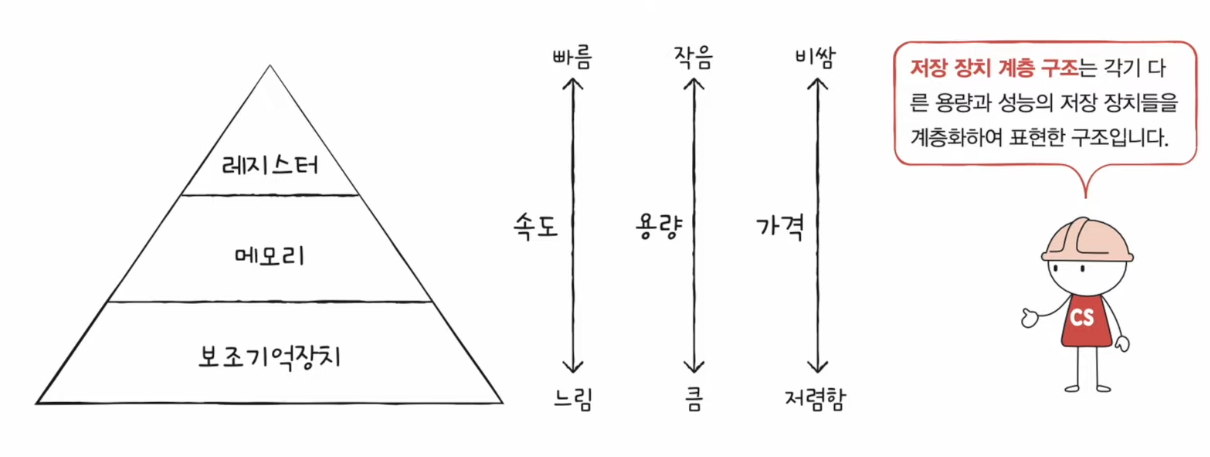
저장 장치의 일반적인 명제 (저장 장치 계층 구조의 개념)
- CPU와 가까운 저장 장치는 빠르고, 멀리 있는 저장 장치는 느리다.
- 속도가 빠른 저장 장치는 저장 용량이 작고, 가격이 비싸다.
- 낮은 가격대의 대용량 저장 장치를 원한다면 느린 속도를 감수해야 하고, 빠른 속도의 저장 장치를 원한다면 작은 용량과 비싼 가격을 감수해야 한다.모든 것을 만족시키기엔 현실적으로 어렵다!
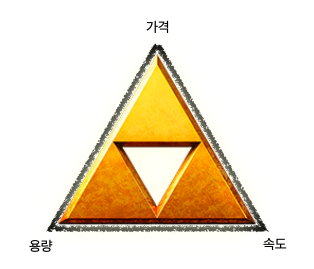
저장 장치의 계층 구조 (memory hierachy)
- 일반적으로 컴퓨터는 다양한 저장 장치를 모두 사용한다.
- 컴퓨터가 사용하는 저장 장치들을 ‘CPU에 얼마나 가까운지’를 기준으로 계층적으로 나타낼 수 있다. → 저장 장치 계층 구조
캐시 메모리
- CPU와 메모리 사이에 위치한, 레지스터보다 용량이 크고 메모리보다 빠른 SRAM 기반의 저장 장치
- CPU의 연산 속도와 메모리의 접근 속도의 차이를 조금이나마 줄이기 위해 탄생
- 매번 CPU와 메모리의 접근이 발생하면 시간이 오래 걸리니, 메모리에서 CPU가 사용할 일부 데이터를 미리 캐시 메모리로 가지고 와서 쓰자는 컨셉
- 저장 장치의 계층 구조상으로는 레지스터와 메모리의 사이에 위치한다.
- 캐시 메모리는 여러 개가 존재하며, CPU(코어)와 가까운 순서대로 계층을 구성한다.
- 코어와 가장 가까운 캐시 메모리를 L1(level 1) 캐시, L2(level 2) 캐시, L3(level 3) 캐시 순서로 나열할 수 있다.
- 용량 : L1 < L2 < L3
- 속도 : L1 > L2 > L3
- 가격 : L1 > L2 > L3
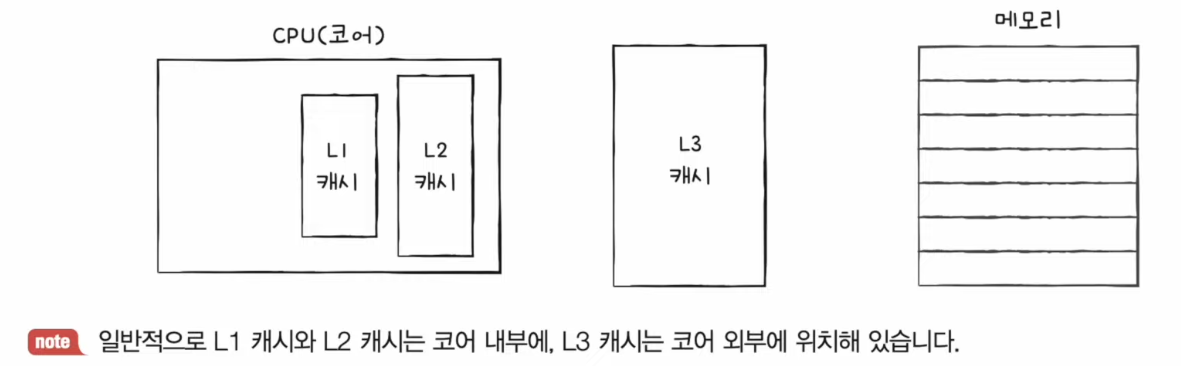
✅ 코어와 가장 가까운 L1 캐시는 조금이라도 접근 속도를 빠르게 만들기 위해 명령어만을 저장하는 L1I 과 데이터만을 저장하는 L1D 캐시로 분리하는 분리형 캐시(split cache)도 존재한다.
✅ 계층을 나누게 된 저장 장치의 특징이 중요하다 (속도, 용량, 가격의 변동)
참조 지역성의 원리
- 캐시 메모리는 CPU가 자주 사용할 법한 내용을 예측해서 저장해야한다.
- CPU가 사용할 법한 데이터를 예측하는 방법을 참조 지역성의 원리라고 한다.
- CPU가 메모리에 접근할 때의 주된 경향을 바탕으로 만들어진 원리
- CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다.
- CPU는 접근한 메모리 공간 근처를 접근하려는 경향이 있다.
참조 지역성의 원리 1
- 변수에 저장한 값을 다시 접근해서 사용하려는 형태
참조 지역성의 원리 2
- 공간 지역성
- 메모리 공간을 구획으로 나누어 만들어진 프로그램은 인접한 영역에서 관련 기능 및 데이터가 존재한다.
캐시 히트
- CPU가 캐시 메모리에 저장된 값을 활용할 경우, 즉 예측이 들어맞을 경우를 ‘캐시 히트’라고 표현한다.
캐시 미스
- CPU가 캐시 메모리에 저장된 값을 활용하지 않는 경우(메모리에 접근해야 하는 경우), 즉 예측이 틀린 경우를 ‘캐시 미스’라고 표현한다.
캐시 적중률
- 캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
- 캐시 적중률이 높을 수록 성능이 좋다 → CPU와 메모리와의 접근 횟수를 줄일 수 있다.
- 최근 CPU의 캐시 적중률은 80퍼센트에 육박한다. (무려!!)
Chapter 7️⃣
07-1 다양한 보조기억장치
하드 디스크
- 자기적인 방식으로 데이터를 저장하는 보조기억장치
- 자기 디스크의 일종
- 실질적으로 데이터가 저장되는 플래터 : 자기 물질로 덮여 있어 N극과 S극의 정보를 저장 (0과 1의 역할)
- 플래터를 회전시키는 스핀들
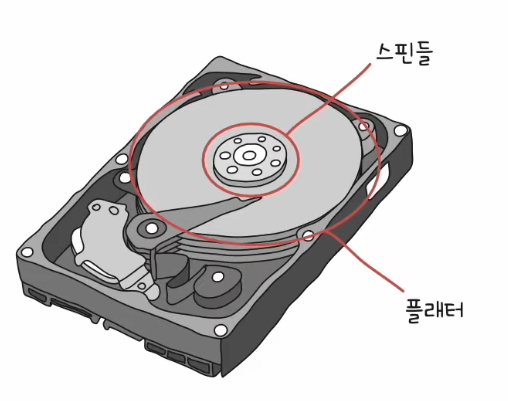
✅ 일반적으로 플래터 양면을 모두 사용한다.
✅ RPM(Revolution Per Minute) : 분당 회전수, 스핀들이 플래터를 돌리는 속도 단위
- 플래터를 대상으로 데이터를 읽고 쓰는 헤드, 플래터 위에서 미세하게 떠 있는 채로 데이터를 읽고 쓴다.
- 헤드를 원하는 위치로 이동시키는 디스크 암, 일반적으로 모든 헤드가 디스크 암에 부착되어 함께 이동한다.
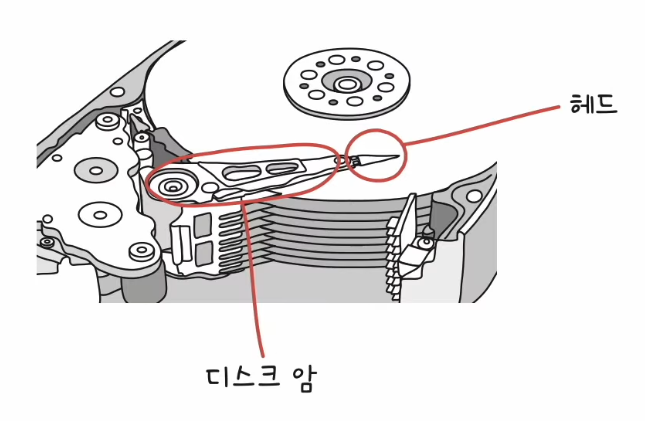
하드 디스크 - 저장 단위
- 기본적으로 트랙(track)과 섹터(sector) 단위로 데이터를 저장
- 플래터를 이루고 있는 동심원을 트랙
- 섹터는 트랙의 일부로 플래터 위의 부채꼴 모양의 영역을 의미
- 섹터의 크기는 512 바이트 ~ 4096 바이트
- 하나 이상의 섹터를 묶어 블록(block)이라고 표현하기도 한다.
- 실린더 : 여러 겹의 플래터 상에서 같은 트랙이 위치한 곳을 모아 연결한 논리적인 단위
- 연속된 정보는 한 실린더에 기록된다. : 헤드를 따로 움직이지 않고 한번에 읽을 수 있기 때문에 (플래터 사이사이에 많기 때문에)
하드 디스크 - 데이터 접근 과정
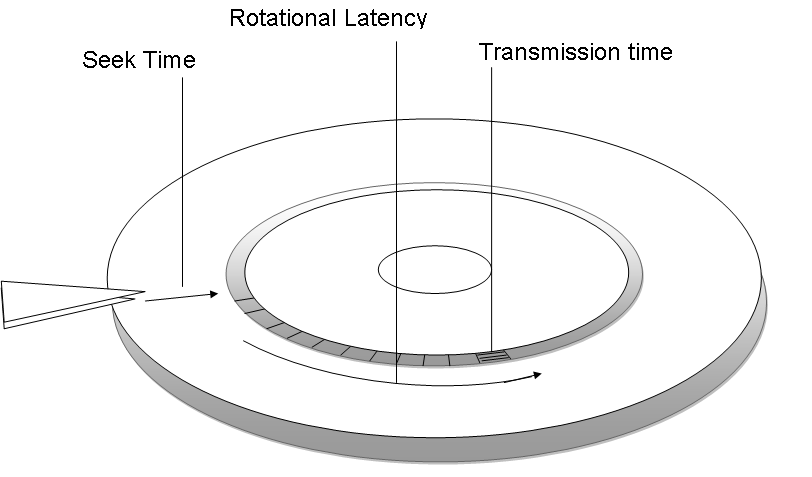
- 하드 디스크가 저장된 데이터에 접근하는 시간을 크게 3개로 나눌 수 있다.
- 탐색 시간 (seek time)
- 회전 지연 (rotational latency)
- 전송 시간 (transfer time)
- 하드 디스크의 작업 성능은 많이 향상되었지만 컴퓨터 작업내에선 정말 많은 시간이 소요된다.
탐색 시간 (seek time)
- 접근하려는 데이터가 저장된 트랙까지 헤드를 이동시키는 시간
회전 지연 (rotational latency)
- 헤드가 있는 곳으로 플래터를 회전시키는 시간
전송 시간 (transfer time)
- 하드 디스크와 컴퓨터 간에 데이터를 전송하는 시간
플래시 메모리
- 전기적으로 데이터를 읽고 쓰는 반도체 기반 저장 장치
- 플래시 메모리는 범용성이 넓어서 보조기억장치에만 쓰이지 않고 다양하게 쓰인다.
✅ 플래시 메모리는 NAND 연산을 수행하는 회로 기반으로 만들어진 NAND 플래시 메모리와 NOR 연산 회로 기반으로 만들어진 NOR 플래시 메모리가 있다. 대용량 저장 장치로 많이 사용되는건 NAND 플래시 메모리이다.
셀 (cell)
- 플래시 메모리에서 데이터를 저장하는 가장 작은 단위
- 셀이 모여서 MB, GB, TB 저장 장치가 된다.
- 한 셀에 1 비트를 저장할 수 있는 플래시 메모리 : SLC
- 한 셀에 2 비트를 저장할 수 있는 플래시 메모리 : MLC
- 한 셀에 3 비트를 저장할 수 있는 플래시 메모리 : TLC
- 한 셀에 4 비트를 저장할 수 있는 플래시 메모리 : QLC
- 셀에 저장할 수 있는 비트 수에 따라 플래시 메모리의 수명, 성능, 가격에 영향을 미친다.
SLC
- 한 셀로 두 개의 정보를 표현할 수 있다.
- 비트의 빠른 입출력
- 긴 수명
- 용량 대비 가격이 높다
MLC
- 한 셀에 네 개의 정보를 표현할 수 있다. (대용량화하기 유리하다.)
- SLC 보다 느린 입출력
- SLC 보다 짧은 수명
- SLC 보다 저렴하다.
- 시중에서 많이 사용 (MLC, TLC, QLC)
TLC
- 한 셀에 여덟 개의 정보를 표현할 수 있다. (대용량화하기 유리하다.)
- MLC 보다 느린 입출력
- MLC 보다 짧은 수명
- MLC 보다 저렴하다.
- 시중에서 많이 사용 (MLC, TLC, QLC)
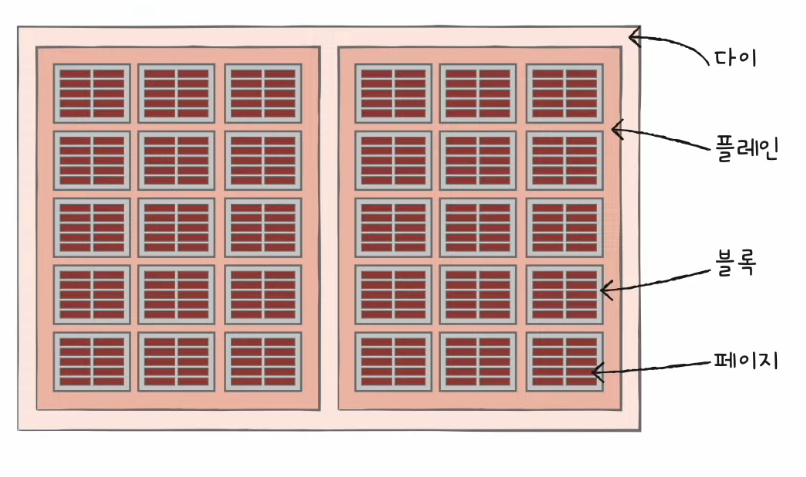
플래시 메모리 - 저장 단위
- 셀들이 모여서 페이지(page)
- 페이지들이 모여서 블록(block)
- 블록이 모여서 플레인(plane)
- 플레인이 모여서 다이(die)
- 읽기와 쓰기는 페이지 단위로 이루어진다.
- 삭제는 (페이지보다 큰) 블록 단위로 이루어진다.
페이지의 상태
- Free 상태 : 어떠한 데이터도 저장하고 있지 않아 새로운 데이터를 저장할 수 있는 상태
- Valid 상태 : 이미 유효한 데이터를 저장하고 있는 상태
- Invalid 상태 : 유효하지 않은 데이터(쓰레기값)를 저장하고 있는 상태
✅ 플래시 메모리는 하드 디스크와 달리 덮어쓰기가 불가능하다. (invalid 상태가 존재한다.)
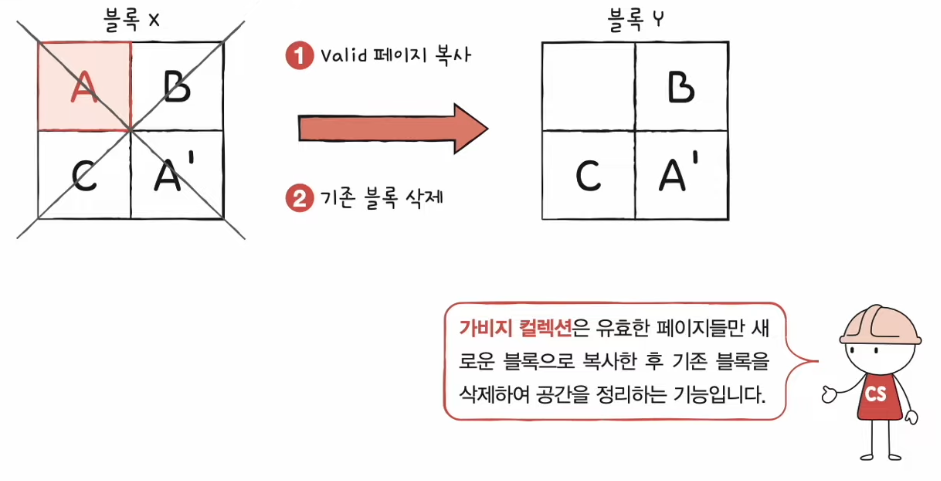
가비지 컬렉션 (garbage collection)
- 플래시 메모리 사용 중에 invalid 페이지가 용량을 차지하므로 공간을 정리하기 위한 기능 (공간을 관리하는 기능)
- 유효한 페이지들만을 새로운 블록으로 복사
- 기존의 블록을 삭제
07-2 RAID의 정의와 종류
RAID (Redundant Array of Independent Disks)
- 하드 디스크와 SSD로 사용하는 기술
- 데이터의 안전성 혹은 높은 성능을 위해 여러 물리적 보조기억장치를 마치 하나의 논리적 보조기억장치처럼 사용하는 기술
RAID 레벨
- RAID를 구성하는 기술
- RAID 0, RAID 1, RAID 2, RAID 3, RAID 4, RAID 5, RAID 6
- 그로부터 파생된 RAID 10, RAID 50 등이 있다.
- RAID 0, RAID 1, RAID 4, RAID 5, RAID 6 이 대중적으로 사용된다.
RAID 0
- 데이터를 단순히 나누어 저장하는 구성 방식
- 각 보조기억장치는 번갈아 가며 데이터를 저장한다.
- 저장되는 데이터가 보조기억장치의 갯수만큼 나뉘어 저장된다.
- 장점 : 입출력 속도의 향상 (여러개의 보조기억장치로부터 동시에 입출력을 발생시킨다.)
- 단점 : 저장된 정보가 안전하지 않음 (하나의 장치만 고장나도 데이터를 사용할 수 없다.)
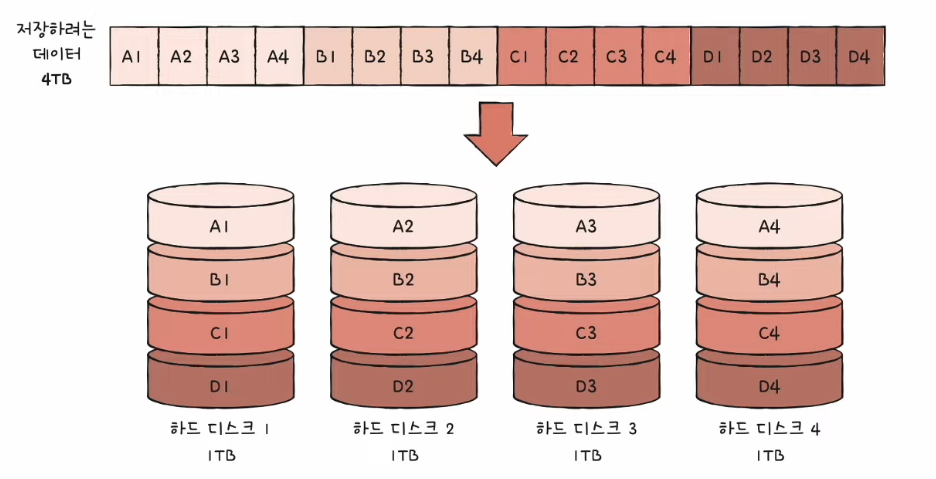
✅ 스트라입 (stripe) : 마치 줄무늬처럼 분산되어 저장된 데이터
✅ 스트라이핑 (striping) : 분산하여 저장하는 것
RAID1
- 미러링 (mirroring) : 복사본을 만드는 방식
- 데이터를 쓸 때 원본과 복사본 두 군데에 씀 (느린 쓰기 속도)
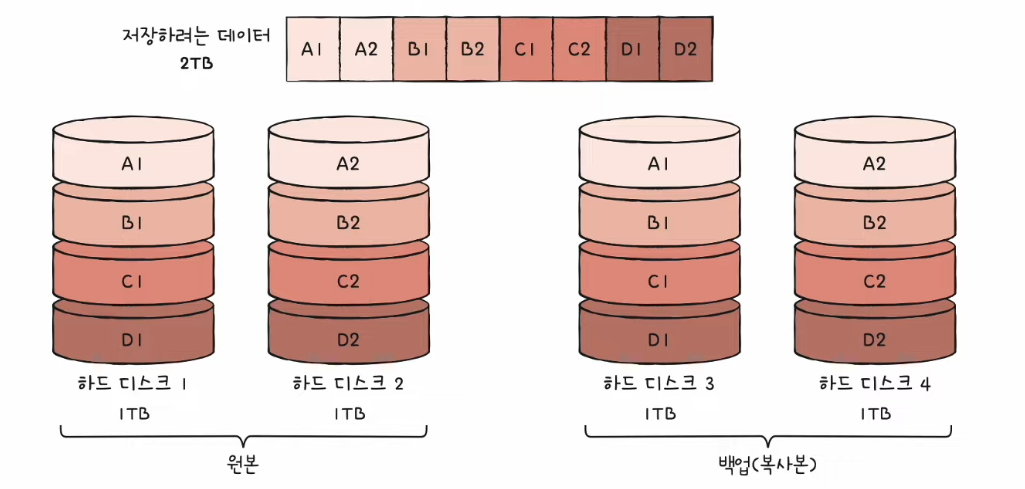
- 장점 : 백업과 복구가 쉽다. (데이터가 안전하다.)
- 단점 : 하드 디스크 개수가 한정되었을 때 사용 가능한 용량이 적어짐
- 복사본이 만들어지는 용량만큼 사용 불가 ➡️ 많은 양의 하드 디스크가 필요 ➡️ 비용 증가
RAID 4
- (RAID 1처럼 완전한 복사본을 만드는 대신) 오류를 검출하고 복구하기 위한 정보를 저장
- 패리티 비트 : 오류를 검출하고 복구하기 위한 정보
- 패리티를 저장한 장치를 이용해 다른 장치들의 오류를 검출하고, 오류가 있다면 복구할 수 있다.

✅ 원래 패리티 비트는 오류 검출만 가능할 뿐 오류 복구는 불가능하다. RAID에서 사용하는 패리티는 오류 검출 뿐만 아니라 복구도 가능하다.
- 단점 : 패리티 디스크의 병목 현상이 발생 할 수 있다. (디스크에 저장될때 마다 패리티 디스크에 저장을 하기 때문에…)
RAID 5
- 패리티 정보를 분산하여 저장하는 방식
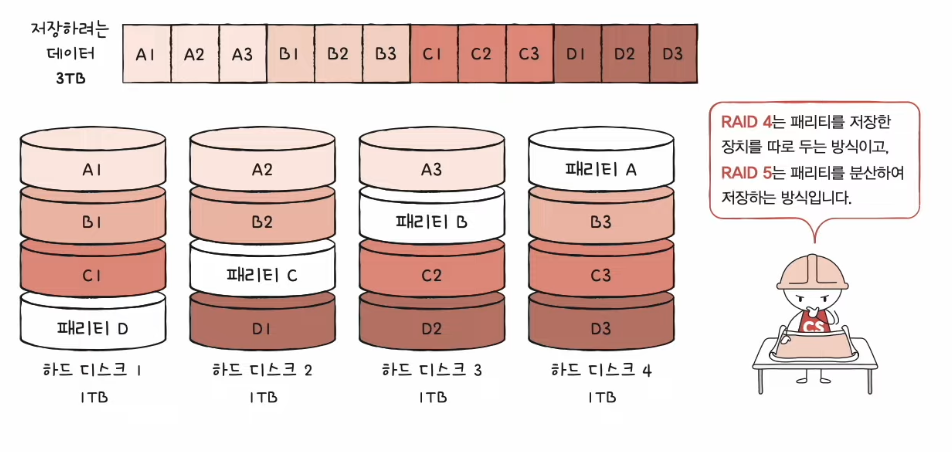
RAID 6
- 두 종류의 패리티 (오류를 검출하고 복구할 수 있는 수단)을 저장한다.
- RAID 5 보다 안전하지만 쓰기는 RAID 5보다 느리다.
정리
- 각 RAID 레벨마다 장단점이 있음
- 어떤 상황에서 무엇을 최우선으로 원하는지에 따라 최적의 RAID 레벨은 달라질 수 있음
- 각 RAID 레벨의 대략적인 구성과 특징을 아는 것이 중요하다.
8️⃣ 입출력장치
08-1 장치 컨트롤러와 장치 드라이버
입출력장치가 CPU, 메모리보다 다루기 까다로운 이유
- 입출력장치는 종류가 너무나도 많다.
- 장치가 다양하면 장치마다 속도, 데이터 전송 형식 등도 다양하다.
- 다양한 입출력장치와 정보를 주고받는 방식을 규격화하기 어렵다.
- 일반적으로 CPU와 메모리의 데이터 전송률은 높지만 입출력장치의 데이터 전송률은 낮다.
- 전송률 (transfer rate) : 데이터를 얼마나 빨리 교환할 수 있는지를 나타내는 지표
장치 컨트롤러
- 위와 같은 어려움을 해결하기 위해 입출력장치는 장치 컨트롤러를 통해 컴퓨터와 연결된다.
- 입출력 제어기 (I/O controller), 입출력 모듈 (I/O module)이라고 불리기도 한다.
장치 컨트롤러의 역할
- CPU와 입출력장치 간의 통신중개 : 까다로운 이유 1번을 해결
- 오류 검출 : 장치의 오류 상태를 확인
- 데이터 버퍼링 : 데이터를 모았다가 조금씩 내보내거나, 한 번에 내보내서 전송률을 맞춰준다. (까다로운 이유 2번)
✅ 버퍼링 : 전송률이 높은 장치와 낮은 장치 사이에 주고받는 데이터를 버퍼라는 임시 저장 공간에 저장하여 전송률을 비슷하게 맞추는 방법
장치 컨트롤러의 구조
- 입출력버스 (시스템버스)에 연결되어 정보를 주고 받게 된다.
- 주고 받는 정보는 크게 3개의 레지스터에 저장된다.
- 데이터 레지스터, 상태 레지스터, 제어 레지스터
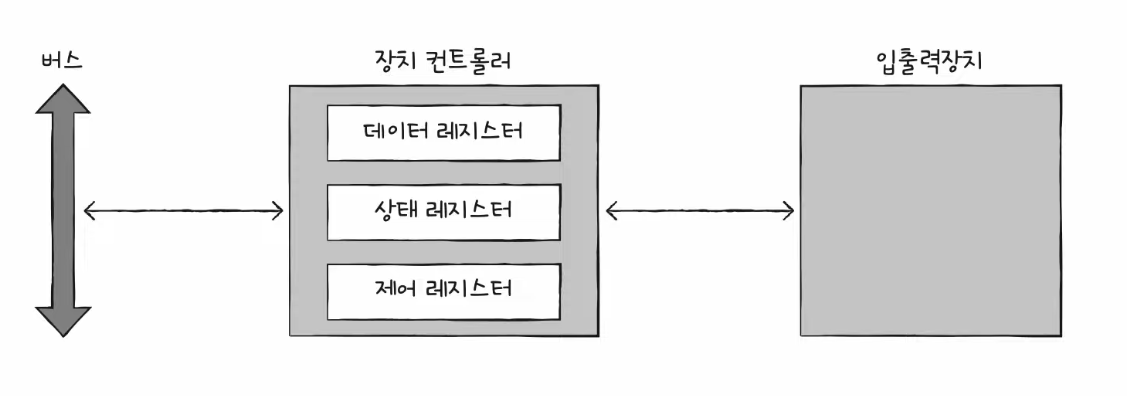
장치 컨트롤러 - 데이터 레지스터
- CPU와 입출력장치 사이에 주고받을 데이터가 담기는 레지스터 (버퍼)
- 최근엔 데이터 양이 많아짐에 따라 RAM을 사용하기도 한다.
장치 컨트롤러 - 상태 레지스터
- 상태 정보 저장
- 입출력장치가 입출력 작업을 할 준비가 되었는지 상태를 저장
- 입출력 작업이 완료되었는지 상태를 저장
- 입출력장치에 오류는 없는지 등의 상태 정보를 저장한다.
장치 컨트롤러 - 제어 레지스터
- 입출력장치가 수행할 내용에 대한 제어 정보
장치 드라이버
- 장치 컨트롤러의 동작을 감지하고 제어하는 프로그램
- 장치 컨트롤러는 입출력장치를 연결하기 위한 하드웨어적인 통로
- 장치 드라이버는 입출력장치를 연결하기 위한 소프트웨어적인 통로
- 컴퓨터(운영체제)가 연결된 장치의 드라이버를 인식하고 실행할 수 있어야 컴퓨터 내부와 정보를 주고 받을 수 있음
08-2 다양한 입출력 방법
입출력 방식
- 프로그램 입출력
- 인터럽트 기반 입출력
- DMA 입출력
프로그램 입출력
- 프로그램 속 명령어로 입출력장치를 제어하는 방법
- 입출력 명령어로써 장치 컨트롤러와 상호작용
- CPU가 장치 컨트롤러의 레지스터 값을 읽고 씀으로써 이루어진다.
- CPU 내부에 있는 레지스터들과 달리 여러 장치 컨트롤러 속의 레지스터들을 모두 알고 있을 수 없다. (메모리 맵 입출력, 고립형 입출력)
메모리 맵 입출력 방식
- 메모리에 접근하기 위한 주소 공간과 입출력장치에 접근하기 위한 주소 공간을 하나의 주소 공간으로 간주하는 방법
- 주어진 메모리내에 주소공간을 ‘메모리를 위한 주소 공간’, ‘입출력장치를 위한 주소 공간’으로 나누어서 관리한다.
- 메모리 접근 명령어 == 입출력장치 접근 명령어
고립형 입출력 방식
- 메모리를 위한 주소 공간과 입출력 장치를 위한 주소 공간을 분리하는 방법
- 주어진 메모리내에 모든 공간을 메모리를 위한 공간이나 입출력장치를 위한 주소 공간으로 쓸 수 있다.
- (입출력 읽기/쓰기 선을 활성화 시키는) 입출력 전용 명령어를 사용한다.
| 메모리 맵 입출력 | 고립형 입출력 |
| 메모리와 입출력장치는 같은 주소 공간 사용 | 메모리와 입출력장치는 분리된 주소 공간 사용 |
| 메모리 주소 공간이 축소됨 | 메모리 주소 공간이 축소되지 않음 |
| 메모리와 입출력장치에 같은 명령어 사용 가능 | 입출력 전용 명령어 사용 |
인터럽트 기반 입출력
- 하드웨어 인터럽트는 장치 컨트롤러에 의해 발생
- 인터럽트 발생전까지 CPU가 다른 작업을 수행할 수 있다 ➡️ 효율적인 방식
✅ 폴링(polling) : 입출력장치의 상태와 처리할 데이터가 있는지를 주기적으로 확인하는 방식, 인터럽트 보다 CPU의 부담이 더 크다.
동시다발적인 인터럽트
- 입출력장치가 많을 때 동시다발적인 인터럽트 요청이 발생한다.
- 플래그 레지스터 속 인터럽트 비트를 비활성화한채 요청을 전부 순차적으로 해결할 순 없다. ➡️ NMI
- 우선순위를 반영해서 다중 인터럽트를 처리해야한다.
✅ NMI (Non-Maskable Interrupt) : 중요도가 높아서 비활성화로 무시할 수 없는 인터럽트
프로그래머블 인터럽트 컨트롤러(PIC, Programmable Interrupt Controller)
- 우선순위를 반영하여 다중 인터럽트를 처리하는 하드웨어
- 여러 장치 컨트롤러에 연결
- 장치 컨트롤러의 하드웨어 인터럽트의 우선순위를 판단한다.
- CPU에게 지금 처리해야 하는 인터럽트가 무엇인지 판단하여 알려준다.
- NMI 우선순위까지 판단하지는 않음
- PIC는 여러개를 사용하여 두 개 이상의 계층적으로 구성한다.
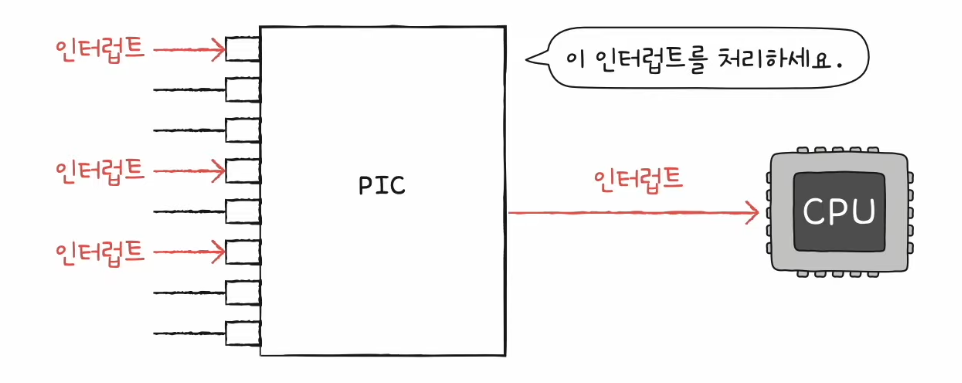
✅ 프로그램 입출력, 인터럽트 기반 입출력의 공통점은 입출력장치와 메모리 간의 데이터 이동은 CPU가 주도하고, 이동하는 데이터도 반드시 CPU를 거친다.
DMA 입출력 (Direct Memory Access)
- 입출력장치와 메모리가 CPU를 거치지 않고도 상호작용할 수 있는 입출력 방식
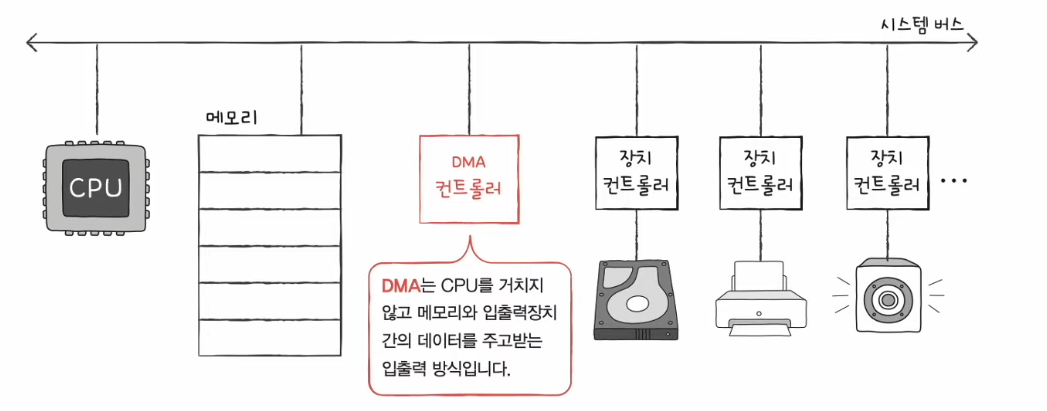
- DMA 컨트롤러라는 하드웨어가 필요하다.
- CPU는 시간을 효율적으로 사용하면서 입출력 장치와 상호작용할 수 있다. (다른 작업에 집중할 수 있다.)
DMA 입출력 과정
- CPU는 DMA 컨트롤러에 입출력 작업을 명령
- DMA 컨트롤러는 CPU 대신 장치 컨트롤러와 상호작용하며 입출력 작업을 수행 (DMA 컨트롤러는 필요한 경우 메모리에 직접 접근한다.)
- 입출력 작업이 끝나면 DMA 컨트롤러는 인터럽트를 통해 CPU에 작업이 끝났음을 알림
- DMA 입출력 과정에서 시스템 버스를 이용 ➡️ 시스템 버스는 공용 자원이기에 동시 사용이 불가능
- CPU가 시스템 버스를 이용하지 않을 때마다 조금씩 시스템 버스를 이용하거나
- CPU가 일시적으로 시스템 버스를 이용하지 않도록 허락을 구하고 시스템 버스를 이용한다.
✅ 사이클 스틸링 (cycle stealing) : CPU 입장에선 시스템 버스에 접근하는 주기를 도둑맞은 기분이 들기에, DMA의 시스템 버스 이용을 사이클 스틸링이라고 부르기도 한다.
입출력 버스
- DMA가 시스템 버스를 불필요하게 점거하는 문제를 해결하기 위해 입출력 버스라는 별도의 버스를 이용한다.
- PCI 버스, PCI express (PCIe) 버스와 입출력 장치를 연결짓는 슬롯
- 슬롯 ➡️ 입출력 버스 ➡️ 시스템 버스
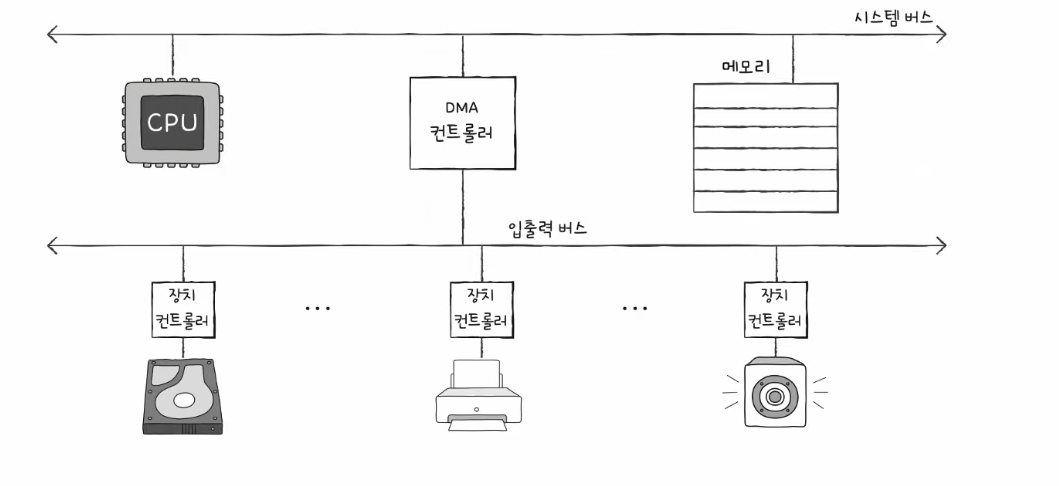
✅ 최근엔 DMA가 더욱 발전해서 입출력 전용 CPU가 만들어지기도 함 ➡️ 입출력 프로세서 혹은 입출력 채널
'혼공컴운' 카테고리의 다른 글
| 혼자 공부하는 컴퓨터 구조+운영체제 6주차 (14~15) (0) | 2023.02.19 |
|---|---|
| 혼자 공부하는 컴퓨터 구조+운영체제 5주차 (12~13) (0) | 2023.02.12 |
| 혼자 공부하는 컴퓨터 구조+운영체제 4주차 (9~11) (0) | 2023.02.05 |
| 혼자 공부하는 컴퓨터 구조+운영체제 2주차 (4~5) (0) | 2023.01.15 |
| 혼자 공부하는 컴퓨터 구조+운영체제 1주차 (1~3) (0) | 2023.01.08 |